

11 AI Concepts Explained, Simply
#138: Break into AI Engineering


Share this post & I'll send you some rewards for the referrals.
I’ve built agents at Google to support their machine learning operations.
Then one thing became super clear to me: AI engineering is good software engineering with an understanding of a few key AI principles.
Just a year ago, hardly any software engineers were building with AI.
Now, engineers are expected to understand AI engineering and integrate AI into their products. This newsletter is a primer to bridge the gap from software to AI engineering.
Onward.
The tax you pay to run multiple agents (Partner)

If you’ve spent any time with coding agents, you know the feeling.
You start the morning with a clean plan. Spin up a few agents. One is refactoring the auth module. Another is writing tests. A third is scaffolding a new API endpoint. You’re flying.
Then, around 10:30 AM, you look up and realize you have 20 terminal windows open. One agent is blocked waiting for a decision you forgot to make. Another finished 40 minutes ago, and you never noticed. A third went sideways three commits back. You’re no longer flying. You’re drowning.
You’ve shifted from human as driver to human as director.
When running coding agents in parallel, the bottleneck isn’t just context. It’s your own attention trying to manage 10 agents across 10 terminals. You’re losing your mind to terminal chaos.
Meet Cline Kanban, a CLI-agnostic visual orchestration layer that makes multi-agent workflows usable across providers. Multiple agents, one UI. It’s the air traffic controller for the agents you’re already running, regardless of where they live.
Interoperable: Claude Code and Codex compatible, with more coming soon.
Full Visibility: Confidently run multiple agents and work through your backlog faster.
Smart Triage: See which agents are blocked or in review and jump in to unblock them.
Chain Tasks: Set dependencies so Agent B won’t start until Agent A is complete.
Familiar UI: Everything in a single Kanban view.
Stop tracking agents and start directing them. Get a meaningful edge with the beta release.
Install Cline Kanban Today: npm i -g cline
(Thanks to Cline for partnering on this post.)
I want to introduce Logan Thorneloe as the guest author.

He’s a software engineer at Google, building at the intersection of machine learning infrastructure, AI agents, and developer tooling.
He uses his background in machine learning research to teach software engineers the AI topics they should know via his newsletter, AI for Software Engineers.
You can also get an exclusive 25% off a paid AI for Software Engineers subscription as a reader of the System Design Newsletter.
1 Software 1.0, 2.0, and 3.0
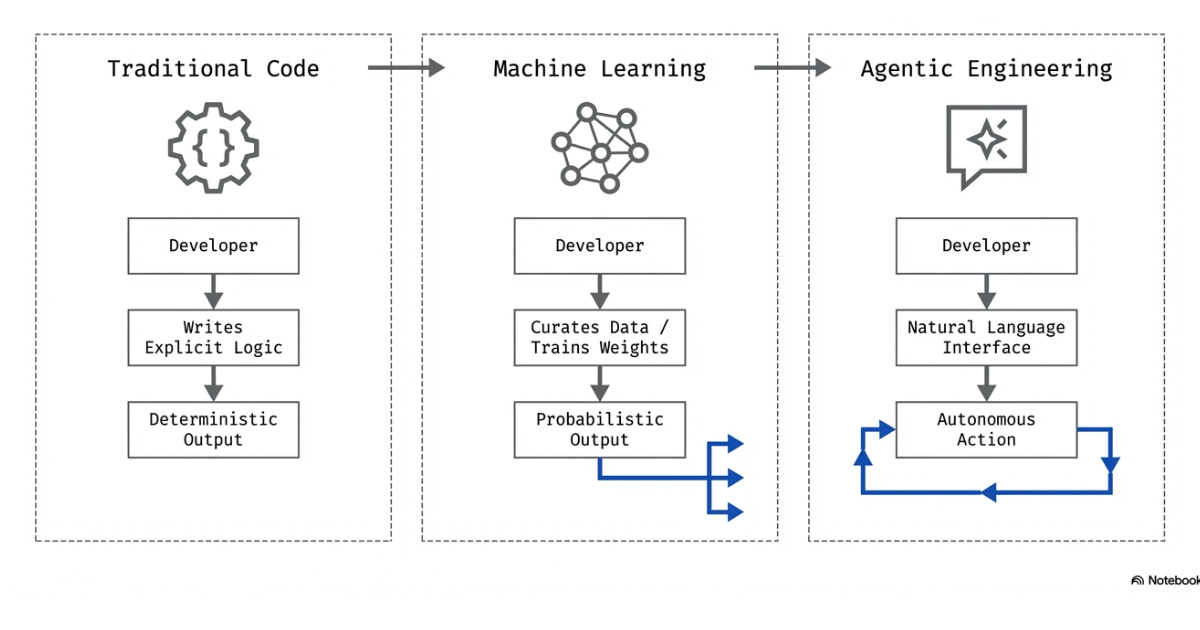
“The hottest new programming language is English.” - Andrej Karpathy
There have been two recent AI-related shifts that have fundamentally changed software development and required software engineers to learn new concepts.
Both changes have been caused by the development of machine learning models: programs trained on data to recognize patterns and make predictions rather than follow explicit rules.
Andrej Karpathy details these changes by describing three different eras of software engineering:
Software 1.0: hand-written logic via writing code. This was the paradigm from the inception of programming all the way to the advent of machine learning.
Software 2.0: shift from explicitly writing logic via code to curating datasets and teaching algorithms to understand them. This shifts logic from a set of instructions to logic learned from data. A good example of this is Tesla’s Autopilot system, shifting from hand-written C++ code to neural networks1 for vision.
Software 3.0: shift toward natural language2 being our new programming interface. This enables engineers to write code by speaking English (vibe coding). It also enables engineers to build agents3, or software that can think and act autonomously.
Software engineers need to understand these key AI principles to be productive in the software 3.0 paradigm…
2 Large Language Models (LLMs)
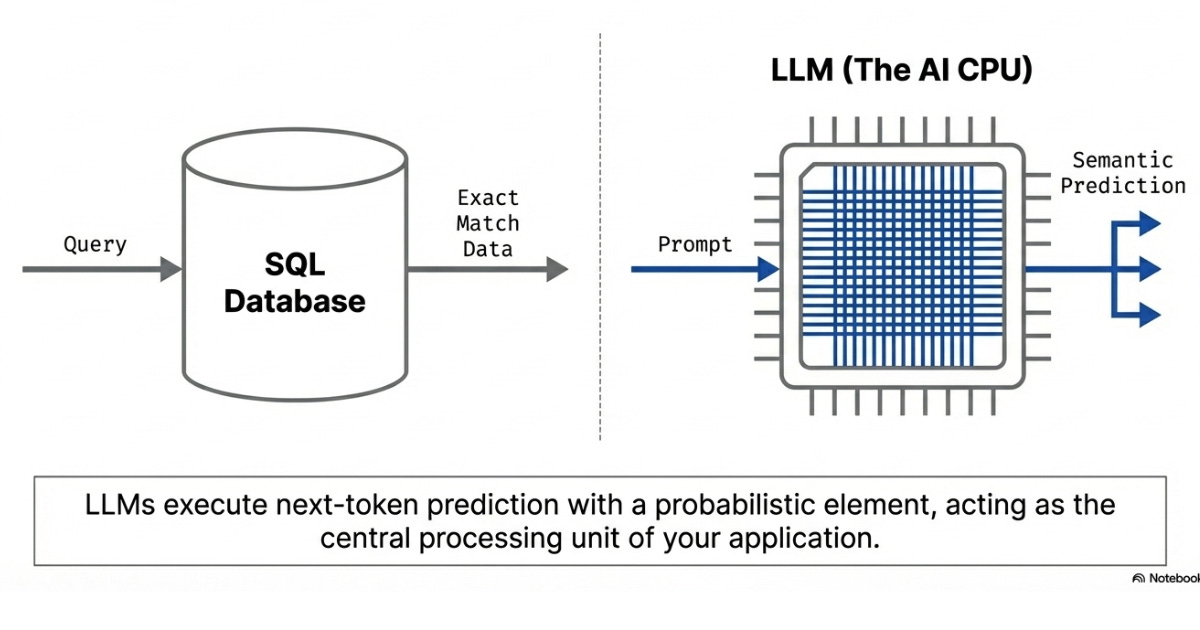
LLMs are natural language AI models trained to predict the continuation of text given a natural language input.
As with any AI model, understanding how it works best comes from examining its training data. LLMs are trained on a massive dataset of text from the internet. They’re trained to learn the relationship between words to best predict an output when given a specific string of inputs.
This relationship enables LLMs to use the knowledge stored in the semantics of language to understand relationships between concepts.
LLMs are also tuned to be non-deterministic; i.e., to provide different answers when an input is sent to the LLM more than once. This ensures an LLM’s output isn’t locked to a given input.
These two concepts make LLMs intelligent.
To relate LLMs to general software engineering, we can think of an LLM as a “non-deterministic database”.
This makes it easier to understand the impact of the knowledge encoded in its weights via semantic understanding. I like to compare it to a SQL database and a query: LLM is the database, and the prompt given to the LLM is the query that extracts the information in the format the user wants.
In AI engineering, it’s apt to think of an LLM as the central processing unit (CPU) of your application. By giving an LLM input information, it can make decisions on its own. Thus, the LLM becomes the CPU for your software, deciding what to do with the information provided.
This is also an apt comparison because choosing an LLM is like picking a CPU.
Each LLM has its own tradeoffs for latency, cost, functionality, and more. Choosing the right model (or models!) is important to meet the requirements of production software systems.
3 Context
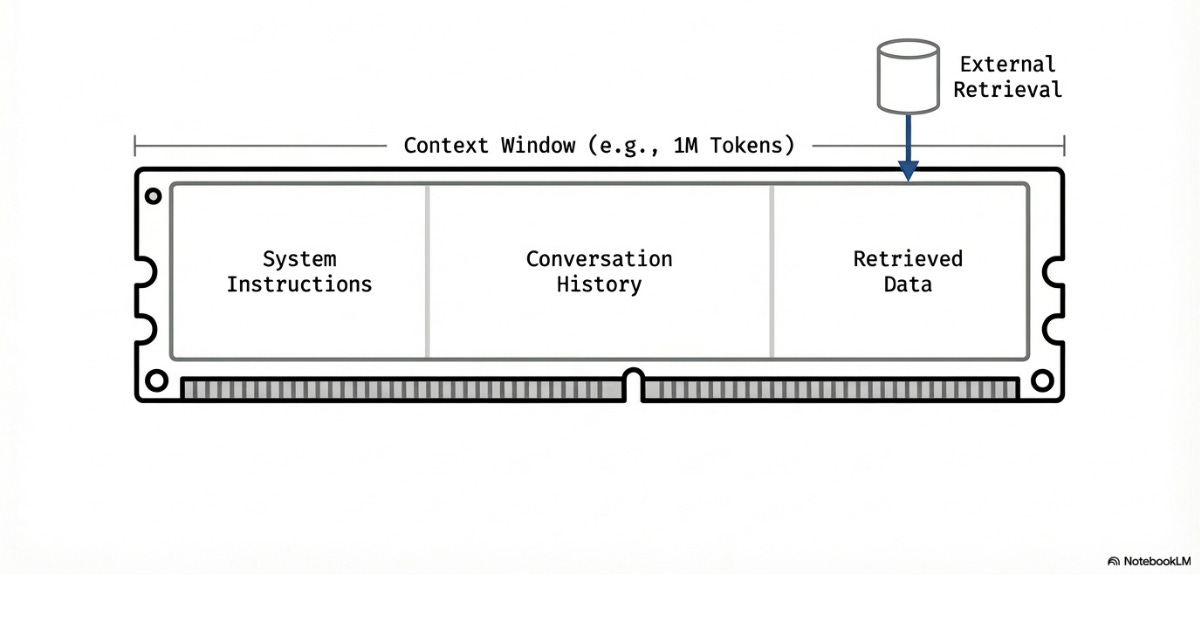
Context is the information LLMs store in their memory and functions as the working memory for a task. For an LLM to perform a task or make a decision, it must have the relevant information in its context window4.
Context works by converting all input into tokens, which are small chunks of text (roughly 3-4 characters each) and feeding them into a model sequentially. The model uses an attention mechanism (a process that calculates how each token relates to every other token in the sequence) to determine which tokens are relevant to each other.
This is how LLMs ‘understand’ the relationships within the input mentioned above.
The tokens currently part of a conversation with an LLM are considered part of that LLM’s “context window”. Each time you interact with an LLM, the model processes the entire context window from scratch. It doesn’t remember the previous turn unless you feed the entire conversation history back in.
Similar to RAM, an LLM’s context window is finite…
There is a hard limit to the number of tokens that can be stored in context at a time. Even before hitting that limit, LLMs tend to bias their knowledge toward the start and end of their context window. This means an LLM’s understanding of the information it is given can degrade before it reaches the hard limit.
The size of an LLM’s context window varies between models.
We’re at a point where frontier models can process 1 million or more tokens, whereas many open models are closer to 256,000 tokens. This isn’t enough for many applications, so it’s important to design AI systems with context limitations in mind.
Also, like RAM, an LLM’s context doesn’t persist between sessions.
LLMs will only remember the context provided during a session. This means AI systems with long-term memory require a more persistent memory storage and retrieval system.
Context is managed by only keeping the tokens a model needs for a task.
To effectively manage context, consider:
Using subagents for specific tasks. A separate agent means a separate context window. That agent can process and summarize the context, then return it to our primary agent.
Summarizing all information currently within an LLM’s context window, clearing the context window, and adding the summary back in. This stores the same information in a shorter context.
Using external systems to store information. Information is only needed in context when it’s being used. It should be stored in a separate, accessible datastore otherwise.
Every AI application built with LLMs needs to properly manage context.
4 Embeddings and Vector Databases
You can’t fit everything into a model’s context window, so you need a way to find relevant information efficiently.
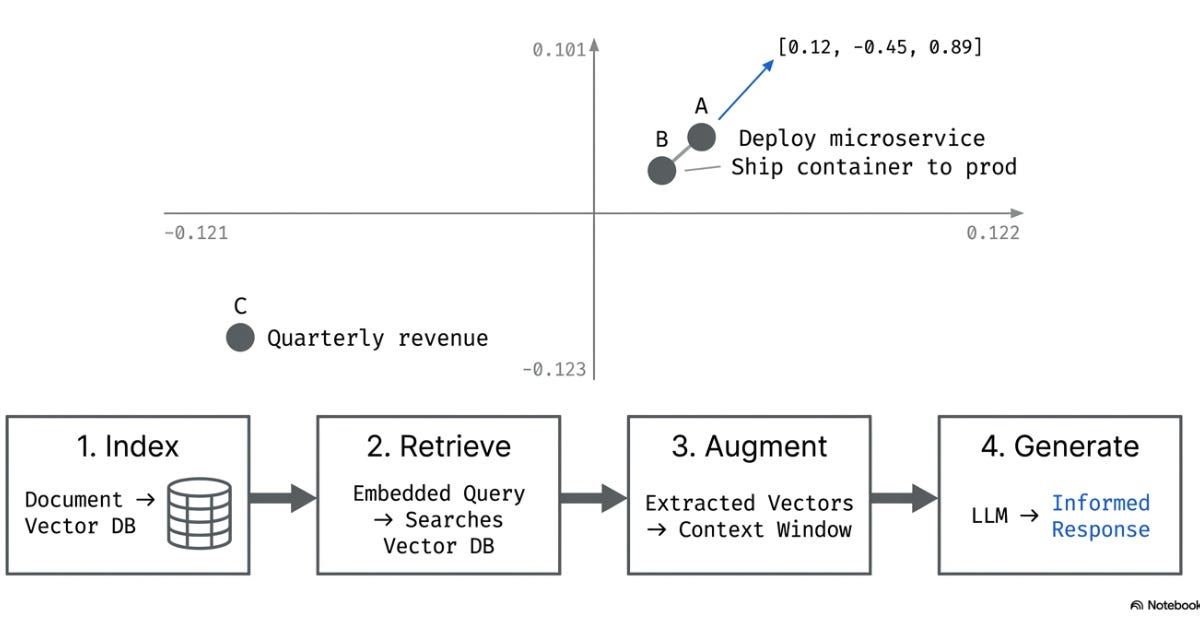
An embedding represents the meaning of data as a list of numbers, called a vector. An embedding can be created from text, audio, video, or any other data format to convey the meaning of that data. Items with similar embedding vectors are considered similar.
Consider a coordinate system in which each axis corresponds to a learned semantic dimension.
“Deploy a microservice” and “ship a container to production” would be plotted close together. “Deploy a microservice” and “quarterly revenue forecast” would be far apart. Embeddings can do this across thousands of dimensions. Distance in this high-dimensional space equals similarity in meaning.
Vector databases5 are built explicitly to store and query embeddings.
They use algorithms optimized for quickly finding the most similar vectors in the database. Those vectors are then added to a model’s context. This is comparable to retrieving data from a cache.
The process follows these steps:
Index: Convert documents into embeddings, store in a vector database
Retrieve: Embed the query and find the most similar documents
Augment: Pass those documents into the LLM’s context window with the user’s question
Generate: LLM answers using retrieved information
Almost every production AI engineering system will need a working memory solution.
Context will need to be augmented with a persistent data store. Embeddings and vector databases.
5 Time to First Token
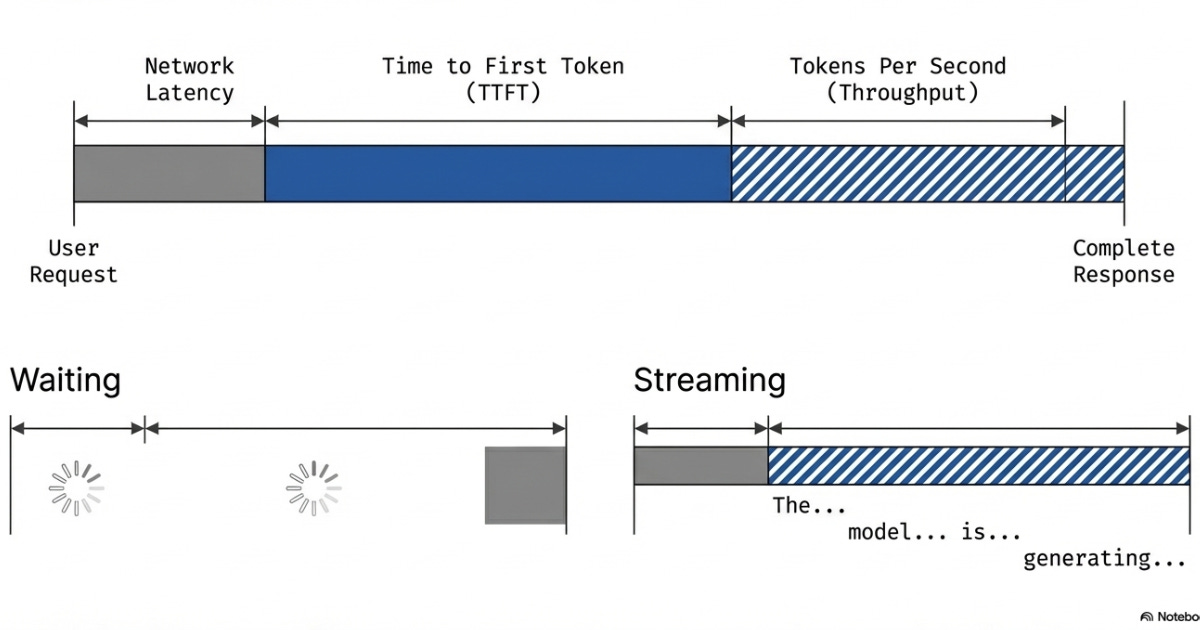
There are many factors to consider when choosing a specific LLM for your production AI system. One of these requirements is latency: your system must function fast enough to be useful.
AI systems must consider the key latency metrics of traditional software systems and the LLM latency metrics, such as:
Time to First Token (TTFT): How long until the model starts responding. This determines perceived responsiveness. Smaller models respond in under a second, but larger models can take several seconds to generate anything.
Tokens Per Second (Throughput): How fast the model generates after starting. This varies significantly across model sizes and compute units, and also affects how quickly the model's response is output to the user.
AI applications require concurrency to stream the output of an LLM call and reduce perceived latency.
Latency is an incredibly important metric to understand the real-world functionality of an AI system.
This is like streaming services, which play the start of a video while loading the rest in the background. This enables the viewer to watch the video before the entire video loads.
6 Evals
“Evals are a new toolset for any and all AI engineers, and software engineers should also know about them. Move from guesswork to a systematic engineering process for improving AI quality.” - Pragmatic Engineer, December 2025
In traditional software, tests are written to ensure code function reliability.
In AI, traditional tests are insufficient for many parts of the system because of their non-deterministic nature. Instead, we write evaluations (evals for short).
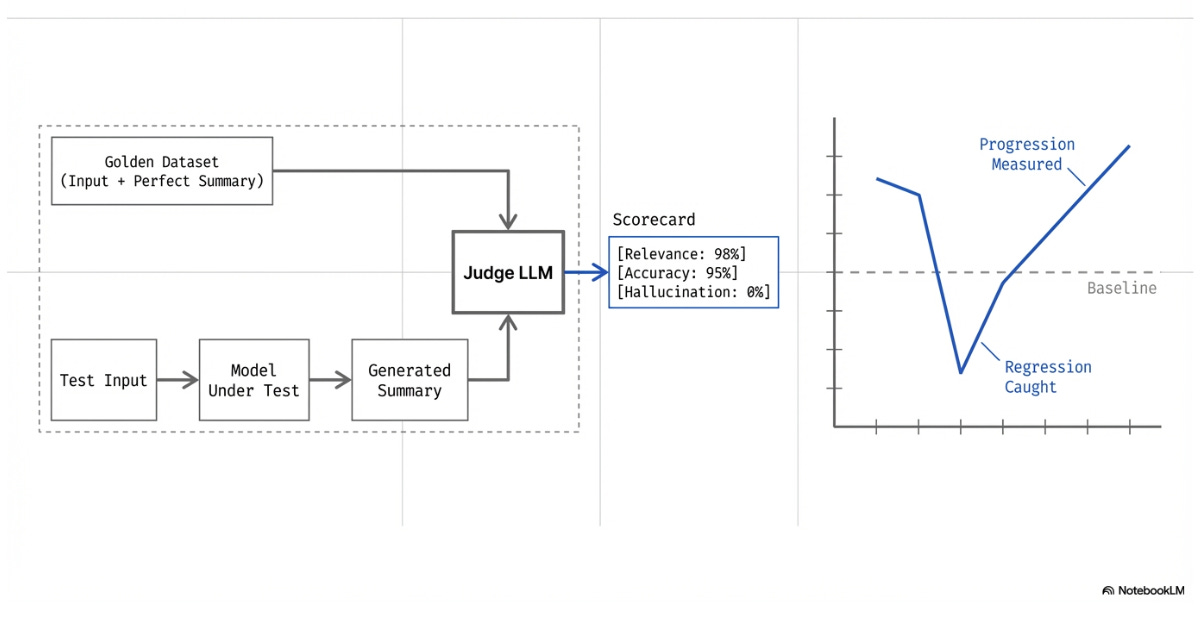
Since assert statements won’t suffice for non-deterministic applications, evals are written using LLM-as-a-judge6.
Essentially, a dataset of inputs and their successful outputs is curated.
This dataset will be used to tell the judge what we’re looking for in our model's output. The LLM-as-a-judge will score how closely the tested model’s outputs resemble the successful output based on given criteria such as relevance, hallucinations, and accuracy.
For example, an eval can be used to assess whether an LLM effectively pulls the important information from a document when summarizing. A set of documents and summarization pairs is gathered as a solution set. The documents are run through the LLM we’re testing, and our LLM-as-a-judge compares the solution for that document to our LLM’s output.
Evals are vital because even the smallest changes in a non-deterministic system can change the user's output. The most common of these changes is model tweaks. Even a small tweak in model performance can drastically change the output of a system.
Evals are written to catch these changes.
7 Agent Loops
Agent loops7 represent the shift from Software 2.0 to Software 3.0.
Software 1.0 to 2.0 was the change from logical control flow to probabilistic output. In the shift to Software 3.0, we see probabilistic output used as reasoning loops in an agentic system8.
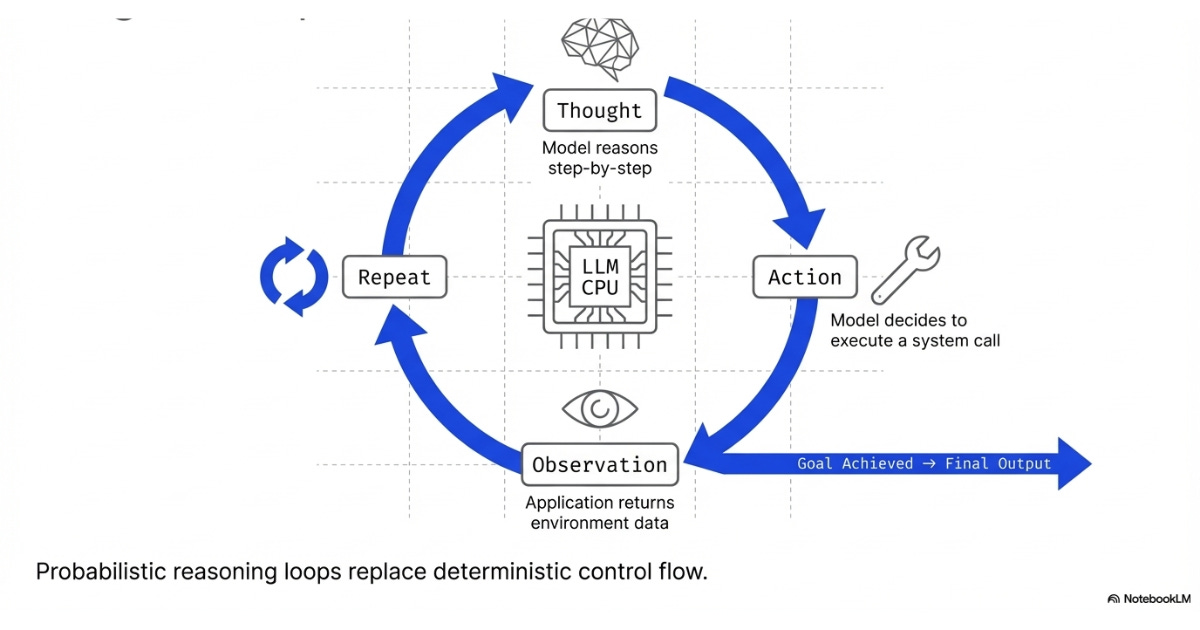
Agent loops enable an LLM to continuously receive and act on information. An agent loop looks something like:
Thought: Model reasons about the current state and what it needs to do next
Action: The model decides to call a tool
Observation: Application executes the tool and returns the result
Repeat: Model then reasons about the observation, takes another action, or provides a final answer
This is the ReAct pattern (Reason + Act), and it has become the default agent loop architecture.
ReAct merges Chain of Thought reasoning, where the model works through a problem step by step, with tool execution into a single loop. This means a model can not only reason to act, but also take its previous actions and their outputs into account, continuously acting until a task is complete.
For example, consider an AI travel agent tasked with booking a trip within a budget.
It first searches for flights and finds the cheapest option. It then reasons about how much budget remains and searches for hotels accordingly. The initial results are all outside the city center, so it adjusts its search criteria and finds a better option. It calculates the total, confirms it fits the budget, and presents the full itinerary.
An agent loop relies on the LLM to determine the next step continuously until it completes a task. This looping process enables an LLM to use its knowledge and context to do meaningful work.
This enables complex workflows that aren’t possible with written code alone.
8 Tool Calling
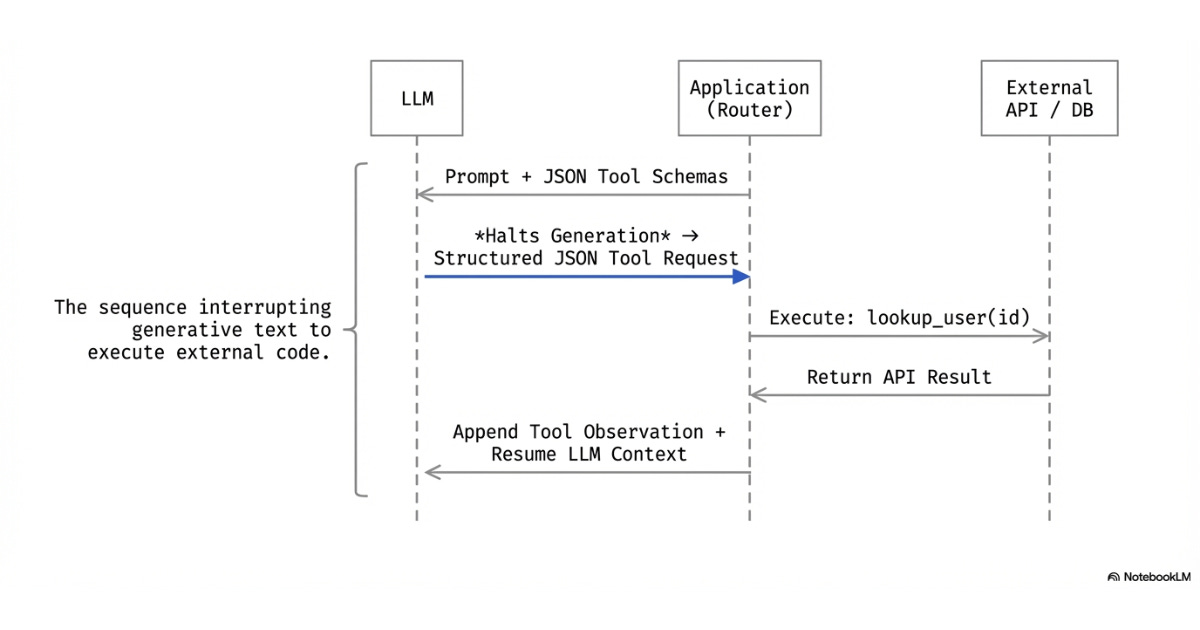
Meaningful work is further enabled by tool calling9 capabilities.
This gives the LLM the ability to do something as part of its action. While LLMs can always output natural language, tool calling enables that output to call functions that perform work.
LLMs cannot execute code, access the internet, or perform other work natively. Instead, tool calling must be enabled:
Keep reading with a 7-day free trial
Subscribe to The System Design Newsletter to keep reading this post and get 7 days of free access to the full post archives.
 | A guest post by
|