
How ML Systems Actually Work: From Data to Deployment
#146: From Embeddings to Feature Stores - 38 Concepts That Power Netflix, Uber, and Spotify


Share this post & I'll send you some rewards for the referrals.
You’ve probably walked into a machine learning (ML) system design interview, been asked to “design a recommendation system,” and suddenly everyone’s throwing around terms like embeddings, feature stores, and model drift, and you’re nodding along while silently drowning.
Most prep resources offer algorithm deep-dives or LeetCode-style drills.
But first, what you actually need is a solid understanding of how ML systems work: vocabulary, building blocks, and how they fit together.
This newsletter is a plain-English field guide to ML system design.
You don’t need to know TensorFlow, write Python, or understand gradient descent math. Just what these terms mean in practice, so you finally understand how these systems actually work.
Along the way, we’ll trace how real systems (like Netflix recommendations, Uber’s ETA predictions, and Spotify’s Discover Weekly) actually work under the hood. Don’t worry about memorizing every detail; this guide exists so your next ML interview feels less like an interrogation and more like a conversation.
Let’s start with the question every ML interview is really asking.
Treat coding agents like services, not terminals (Partner)

You use Claude Code, Codex, Cursor, or Gemini in your terminal every day. What if you could call them in code?
AgentField just open-sourced harness orchestration.
Call those same coding agents programmatically from Python, TypeScript, or Go.
Compose them into real automations: ship a PR, audit a cloud, run a code review - end-to-end pipelines, not toy demos.
For the architecture rationale, their latest post - harness-as-membrane - is worth a read.
(Thanks to AgentField for partnering on this post.)
I want to introduce Paolo Perrone as a guest author.

He’s an ML engineer with 8+ years of production AI experience, read by 1M+ AI/ML engineers on LinkedIn and Substack. He runs a tech content agency serving NVIDIA, Google, and Y Combinator, and writes The AI Engineer, the newsletter that makes engineers dangerously good at AI engineering.
What is an ML System?
Traditional software runs on rules you write by hand.
If the temperature is above 90°F, turn on the AC. If the user clicks “buy,” charge the card. Every decision is hardcoded in code.
ML systems work differently.
Instead of writing rules, you feed the system examples (thousands or millions of them), and it figures out the rules on its own. Show it a million past rides, and it learns to predict how long your Uber will take. Show it billions of watch sessions, and it learns which movie to recommend next.
This sounds magical, but it’s just data engineering. Data flows in, patterns get extracted, predictions flow out, and the system keeps learning from its own results.

Every concept in this newsletter maps to a stage in this pipeline.
Master the pipeline, master the interview…
Raw Material: How Data Becomes Intelligence
You can have the fanciest model in the world. If your data is garbage, your predictions will be garbage.
1. Features
A feature is a single, measurable piece of information model uses to make predictions.
Think of features as the columns in a spreadsheet that describe each example.
If you’re predicting whether someone will click on an ad, your features might include the user’s age, the time of day, the device they’re using, and how many ads they’ve already seen this session. Each of these gives the model a different angle on the same question.
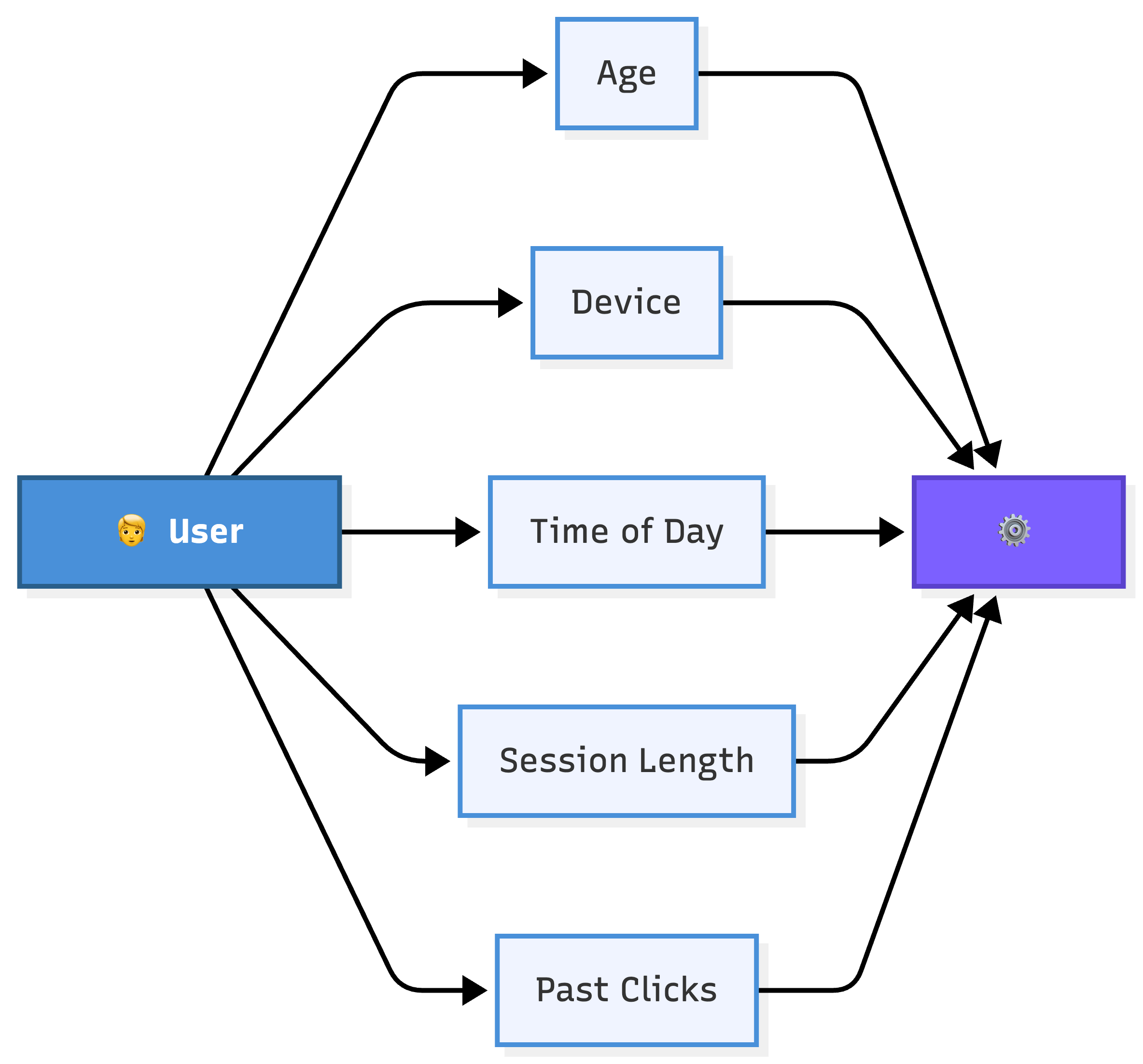
In Spotify’s Discover Weekly, features might include your most-played genres, the time of day you usually listen, and how often you skip songs. The model doesn’t “hear” the music. Instead, it reads the features.
The quality of your features often matters more than the sophistication of your model. Which raises the question: where do good features come from?
2. Feature Engineering
Feature engineering is the process of transforming raw data into features that help a model learn better.
Raw data is messy and unstructured. Feature engineering is about cleaning it up, reshaping it, and extracting the signal.
Think of it like preparing ingredients before cooking. You don’t throw a whole chicken into the pan. You cut it, season it, and lay it out first.

For example, Uber’s raw data might say “ride requested at 2024-12-25 08:47:32 UTC.”
Feature engineering transforms that into: day of week (Wednesday), time of day (morning rush), holiday (yes), weather (rainy). Each transformation gives the model a more useful signal than the raw timestamp alone.
Sometimes the most powerful features aren’t in the raw data at all. A feature like “average number of rides this user takes per week” requires aggregation across many records. That kind of creativity is what separates good feature engineering from great ones.
But features alone aren’t enough. The model also needs to know what the “right answer” looks like.
3. Labels & Ground Truth
A label is the answer you’re training the model to predict. Ground truth is what actually happened in the real world.
If you’re building a spam filter, the label for each email is “spam” or “not spam.” If you’re predicting home prices, the label is the actual sale price. The model learns by comparing its guesses against these known answers.
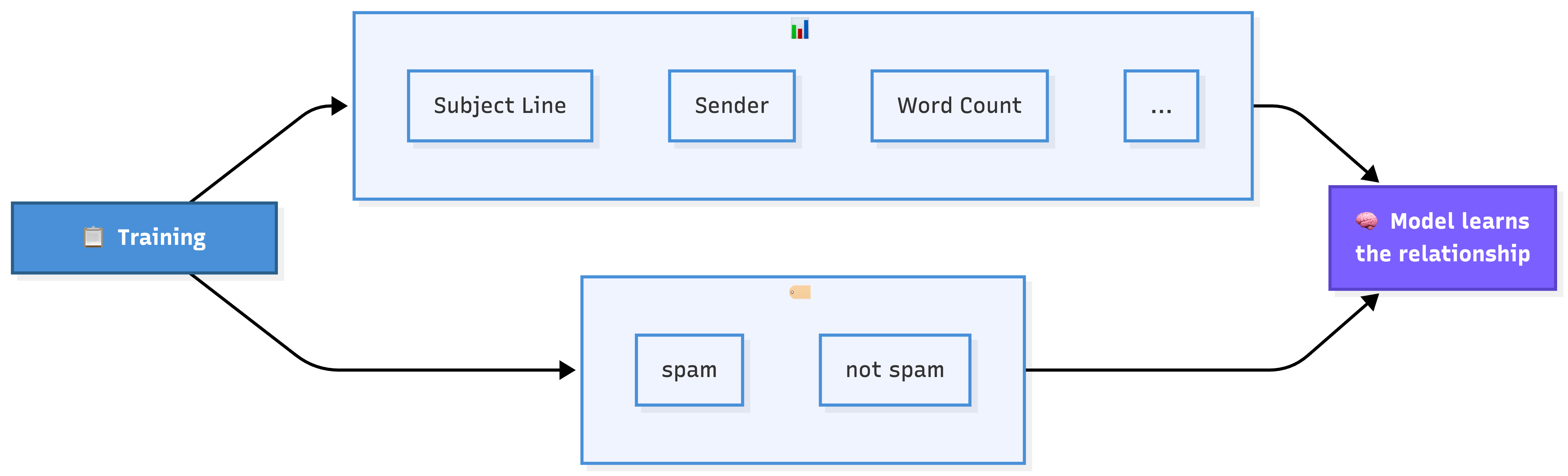
Ground truth sounds simple, but it’s often surprisingly hard to get right.
When Netflix asks “did the user enjoy this movie?”, the ground truth is ambiguous. Did they watch to the end? Did they rate it? Did they watch something similar next? Different definitions of ground truth lead to different model behaviors.
💡 How you define your label shapes what the model actually learns. Choose carefully. Pick the wrong definition of success, and the model will optimize for the wrong thing.
With features and labels defined, the next step is splitting the data so the model can actually learn and prove it learned the right things.
4. Training, Validation & Test Sets
You don’t test a student with the same questions they practiced on.
The same principle applies to ML. The data gets split into three groups, each with a specific job.
Training set is what the model actually learns from. It sees these examples during training.
Validation set is your mid-training checkpoint. It tells you which model version performs best.
Test set is the final exam. If the model performs well here, it’s ready for the real world.
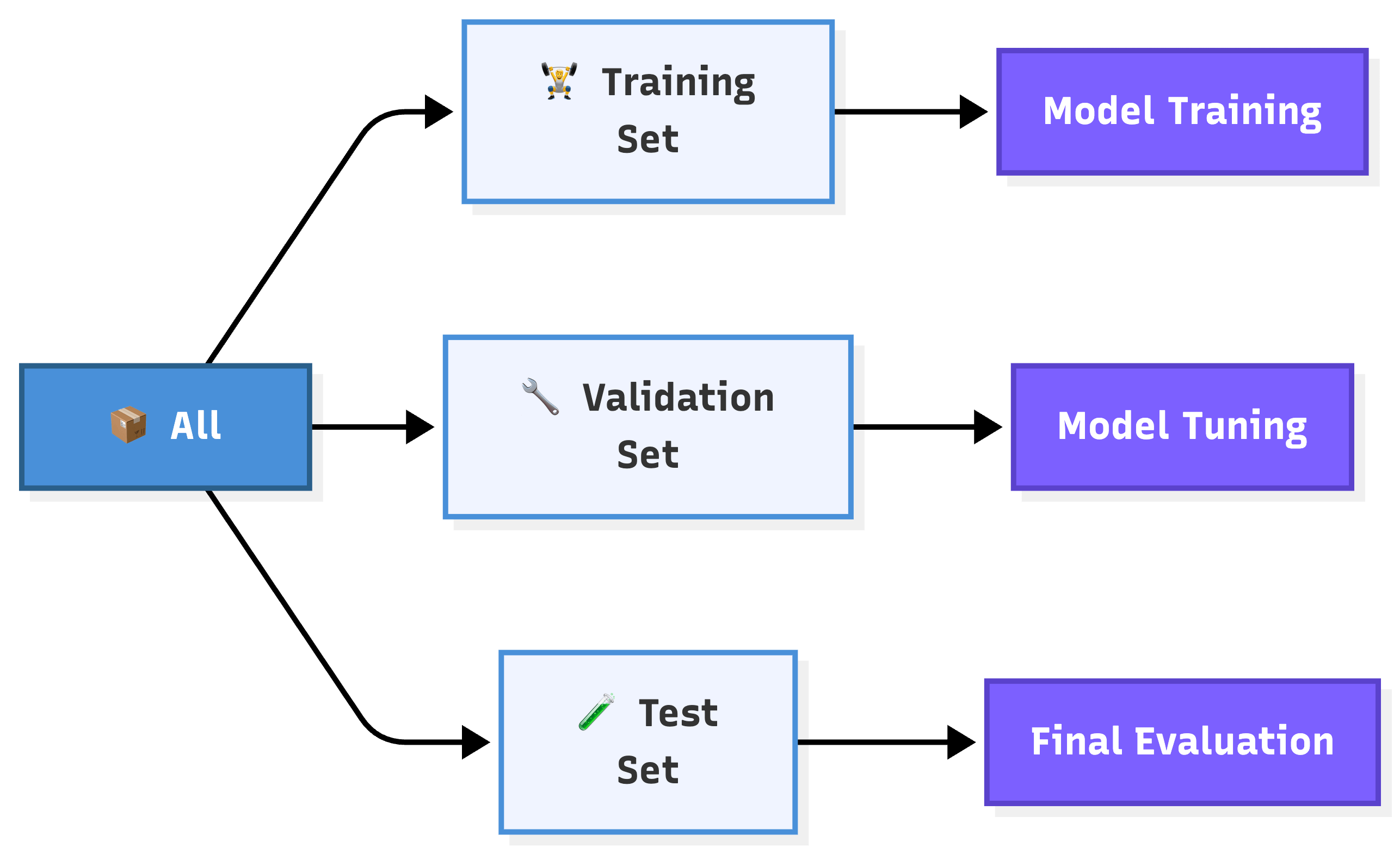
Most teams split their data 70/15/15 or 80/10/10.
The exact ratio depends on how much data you have, but one rule is non-negotiable: test set must never influence model development. Otherwise, you’ve let the student peek at the final exam.
At Netflix, this might mean training on viewing data from January through October, validating in November, and testing in December. This time-based split is especially important for ML systems because real-world data changes over time, a pattern we’ll revisit in Section 5.
Now that we have our data organized, there’s one more data problem that trips up many real-world systems.
5. Class Imbalance & Data Leakage
Class imbalance happens when one outcome is far more common than the others.
In fraud detection, maybe 1 in 10,000 transactions is fraudulent. In medical diagnosis, most patients don’t have the rare disease. The model can achieve 99.99% accuracy by simply predicting “not fraud” every time and still be completely useless.
Fixing class imbalance usually involves techniques like oversampling the rare class, undersampling the common class, or adjusting the model’s loss function to penalize mistakes on rare examples more heavily.
Data leakage occurs when the answer is hidden within the training data.
You’re building a model to predict late deliveries, but your dataset includes “customer complaint filed.” That complaint only exists because the delivery was already late. Of course, the model looks accurate. Remove that feature, and it’s useless.
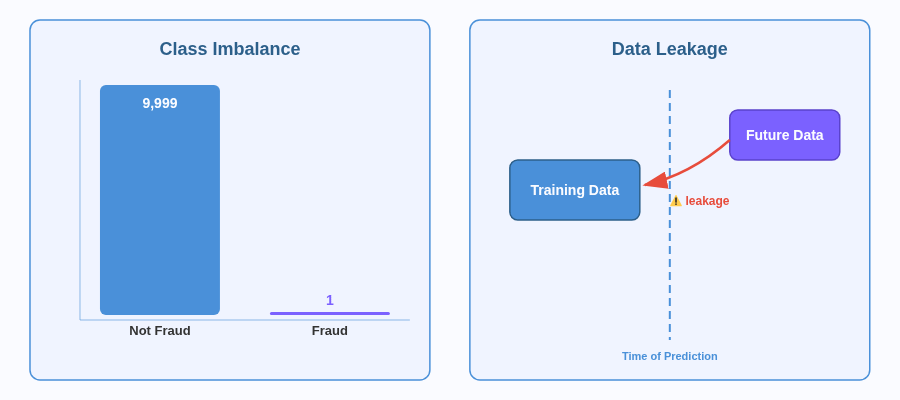
💡 If your model scores above 95% on the first try, check for leakage. If it scores above 99%, check for class imbalance too.
Clean data is only useful if it actually reaches your model. That’s where pipelines come in.
6. Data Pipelines & ETL
Data pipelines are automated workflows that move data from its raw sources (databases, event logs, third-party APIs) through a series of transformations and into a format the model can use.
ETL stands for Extract, Transform, Load. Extract the raw data from its source.
Transform: clean, join, aggregate, and engineer features from it. Load the results into a feature store or a training dataset.
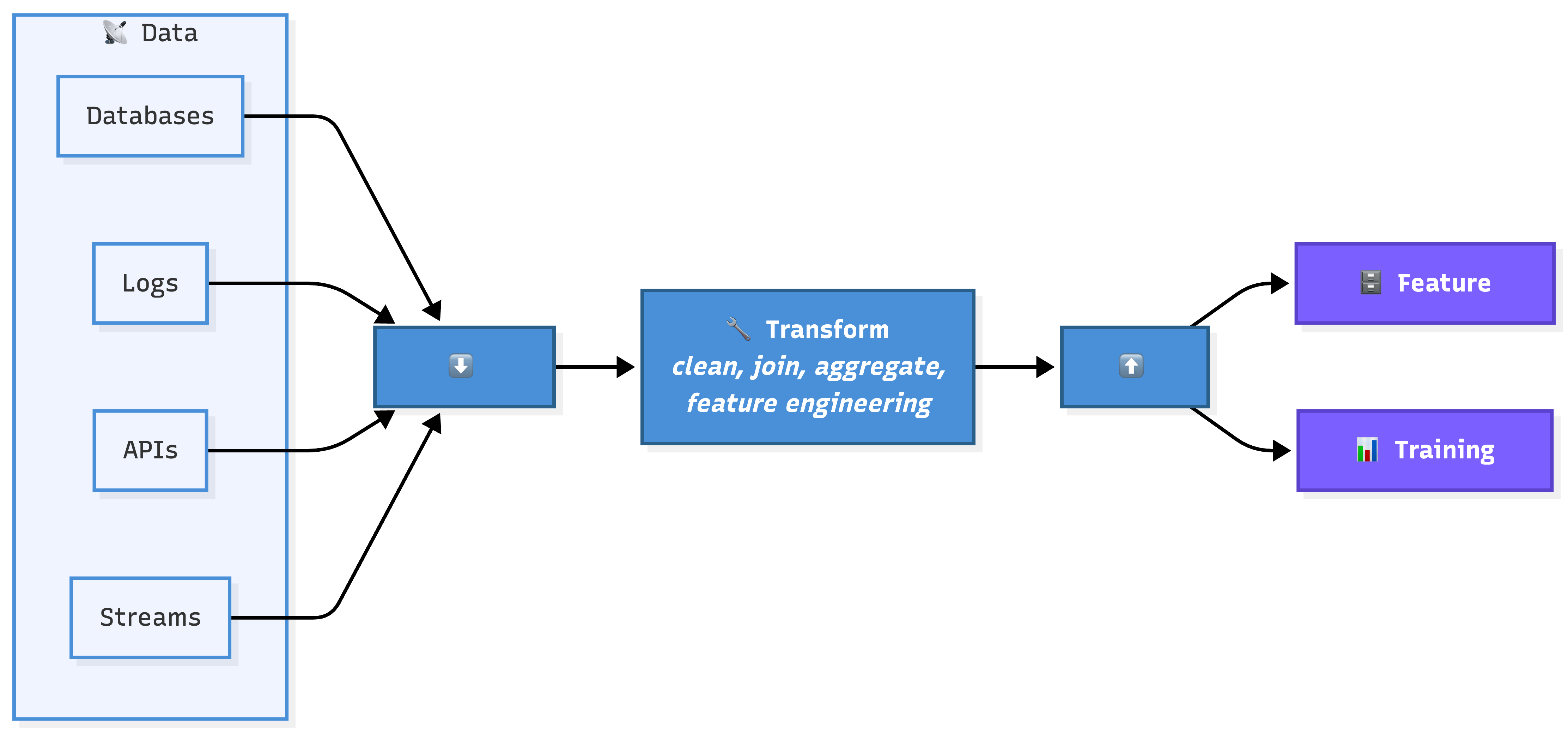
This is the plumbing part of ML.
And like real plumbing, nobody thinks about it until something breaks. Not the model, not the algorithm. A dropped row, a null value, a late pipeline run. No errors thrown, just silently worse predictions.
Uber runs thousands of data pipelines daily. Everyone has monitoring, alerting, and quality checks. Bring this up in an interview, and you’ll immediately stand out as the guy who actually thinks about how ML works in practice.
Pipelines produce data, but how do you keep track of which data a given model was trained on?
7. Data Versioning
Data versioning means tracking exactly which version of a dataset was used to train each model.
Just like software engineers use Git to track code changes, ML teams need to track data changes.
Why does this matter? Imagine your model’s performance suddenly drops. Without data versioning, you have no way to answer: “What changed? Was it the model or the data?” With versioning, you can compare the current training data with previous versions and pinpoint exactly what changed.
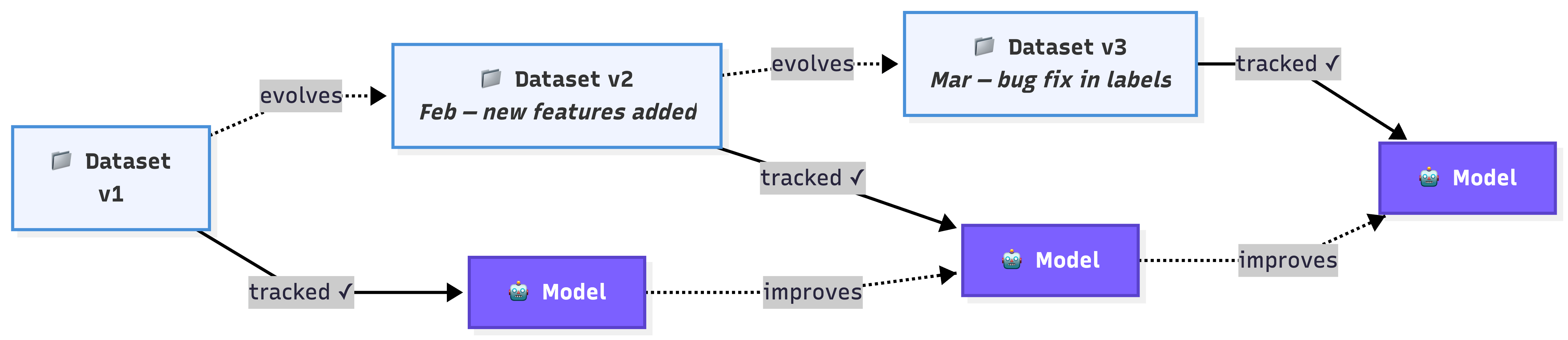
Data versioning also enables reproducibility, a requirement in regulated industries like finance and healthcare.
If an auditor asks, “Why did the model make this decision six months ago?”, you need to be able to recreate the exact model and training data from that point in time.
Tools like DVC (Data Version Control) and MLflow help teams manage this.
In an interview, mentioning data versioning shows you understand that ML systems aren’t just about models. They’re about the entire lifecycle of data and code working together.
With clean, well-structured, and tracked data in hand, it’s time to teach the model how to find patterns in it.
Pattern Machines: How Models Actually Learn
A model doesn’t “know” anything. It finds patterns in data and uses them to make predictions.
8. Model Training & Loss Functions
Model training is the process of showing the model examples and letting it adjust its internal settings until its predictions get closer to the ground truth.
Think of it as a student taking practice tests over and over, getting a little better each time.
The mechanism that drives improvement is the loss function. A loss function measures how wrong the model’s predictions are. After each batch of examples, the model calculates the loss (how far off it was) and adjusts its internal settings to reduce that number.
Over millions of examples, those small adjustments add up.

Different problems need different loss functions.
Predicting a number (like Uber’s ETA) might use mean squared error, penalizing big misses more than small ones. Classifying something (like spam vs. not spam) typically uses cross-entropy loss, which measures how confident the model was in the wrong answer.
The choice of loss function shapes what the model optimizes for. A model trained with mean squared error will try to be accurate on average. A model trained with mean absolute error will be more robust to outliers. Small decisions here have big downstream effects.
But what exactly is the model adjusting? That’s where parameters come in.
9. Parameters & Hyperparameters
Parameters are what the model actually learns.
Think of them as the model’s memory: every pattern gets encoded as a number. GPT-4 has hundreds of billions. A simple recommendation model, a few million. You don’t write them. The model discovers them on its own.
Hyperparameters are the settings that control how the model trains.
You set them before training starts: how fast the model adjusts (learning rate), how many examples it processes at once (batch size), how many times it loops through the data (epochs), and the model’s architecture.

If the model is a student, parameters are the knowledge in their head, and hyperparameters are the study plan: how many hours a day, which subjects first, and how many practice tests.
Bad hyperparameters can make a good model fail.
A learning rate that’s too high, and the model never converges. Too low, and it takes forever to train. Too few epochs and it underfits. Too many and it overfits. In practice, teams run many training experiments with different hyperparameters and compare results on the validation set.
There’s one type of parameter that powers almost every ML system you’ll encounter in interviews: embeddings.
10. Embeddings
An embedding is a way to represent something (a word, a user, a product) as a list of numbers that captures its meaning.
Instead of treating “cat” and “kitten” as completely different labels, embeddings place them close together in a vectorial space because they’re related concepts.
Think of it as a map. On a regular map, cities that are near each other geographically are plotted close together. In an embedding space, concepts that are similar in meaning are plotted close together. “Comedy” and “rom-com” would be neighbors; “horror” would be distant, but still in the same galaxy as other genres. “Accounting” would be in another universe.
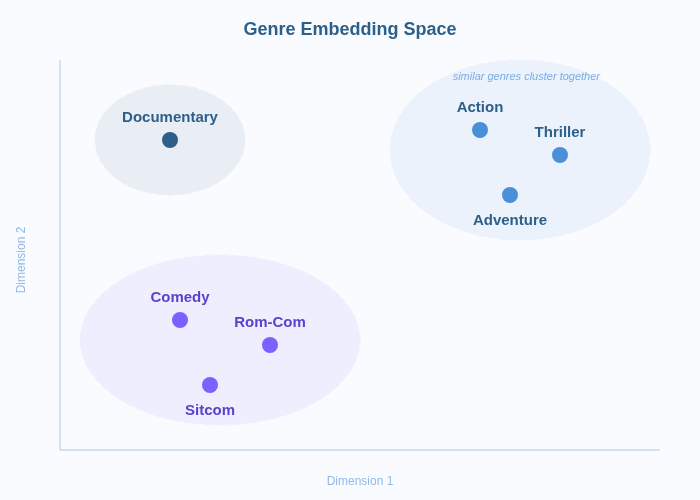
Embeddings are everywhere in real ML systems.
Spotify uses song embeddings to find tracks that are musically similar to what you’ve been listening to. Netflix uses movie embeddings and user embeddings to match viewers with films they’re likely to enjoy.
Embeddings are how ML systems make sense of the real world. A user, a product, a sentence. Turn them into vectors, and suddenly you can calculate which ones are similar, which ones are related, and which ones to recommend.
With all this learning machinery, there’s a critical danger: the model might learn too well.
Reminder: this is a teaser of the subscriber-only newsletter, exclusive to my golden members.
When you upgrade, you’ll get:
High-level architecture of real-world systems.
Deep dive into how popular real-world systems work.
How real-world systems handle scale, reliability, and performance.
Let’s keep going!
11. Overfitting & Regularization
Keep reading with a 7-day free trial
Subscribe to The System Design Newsletter to keep reading this post and get 7 days of free access to the full post archives.
 | A guest post by
|