

I struggled with system design until I learned these 114 concepts
#129: Part 3 - Webhooks, WebRTC, CQRS, and 35 others.

Share this post & I'll send you some rewards for the referrals.
Block diagrams created using Eraser.
No time for small talk today:
Following is the third of a premium 3-part newsletter series... if you want to be successful with system design in 2026, then this newsletter is for YOU.
On with part 3 of the newsletter:
===
Some of these are foundational, and some are quite advanced. ALL of them are super useful to engineers building production-ready systems.
Curious to know how many were new to you:
Webhooks,
WebRTC,
CQRS,
Event Sourcing,
Service Discovery,
Circuit Breaker Pattern,
Bulkhead Pattern,
Strangler Fig Pattern,
Backend for Frontend.
Sidecar Pattern,
Service Mesh,
Observability,
Logging,
Metrics,
Distributed Tracing,
Correlation IDs,
Full-Text Search Engine,
Time Series Database,
Vector Database,
Materialized Views,
Query Optimization,
Connection Pooling,
Cache Stampede,
Cache Warming,
PACELC Theorem,
Security Secrets Management,
Role-Based Access Control,
Single Sign-On,
Checksums,
Bloom Filter,
B-trees and B+ trees,
LSM Tree,
Merkle Tree,
HyperLogLog,
Batch vs Stream Processing,
ETL Pipelines,
MapReduce,
Erasure Coding.
For each, I’ll share:
What it is & how it works--in simple words
A real-world analogy
Tradeoffs
Why it matters
Let’s go.
The best way to build any app (Partner)

Most “AI app builders” aren’t actually app builders. They are infrastructure middlemen. You live inside their box, choose from their secret stack, and force you to start over the moment you want to use a different database, payment processor, or tool.
With Orchids:
You’re not locked-in to Supabase or Stripe.
Not forced to spend credits, bring your own AI subscriptions with you.
One-click deployment straight to Vercel
Build anything. From web, mobile, internal tools, browser extensions, scripts, and bots. Orchids.app is capable of building anything that you can put your mind to.
Use this discount code to get a onetime 15% off during checkout: MARCH15
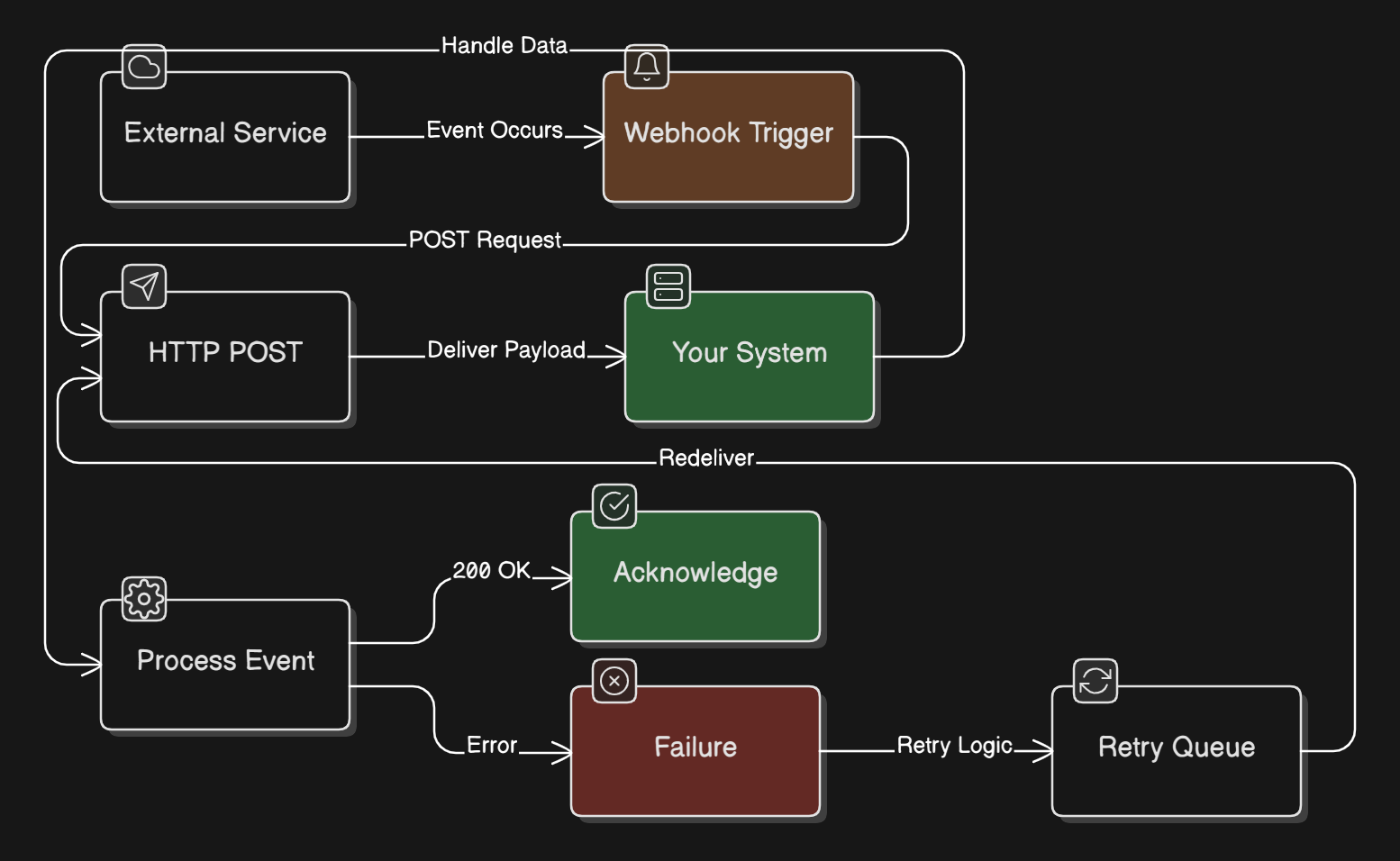
77. Webhooks
Webhooks are HTTP callbacks that allow one system to notify another system when an event occurs by sending a POST request to a configured URL.
Instead of constantly polling for updates, the source system pushes data to your endpoint when something happens.
You register a URL with the provider, and they call it when events trigger. Webhooks enable real-time, event-driven integrations between systems.
Analogy
A doorbell that alerts you when someone arrives instead of you checking the door every few minutes…
When a package arrives, the delivery person rings the bell, and you respond immediately. You don’t waste time repeatedly checking if anyone’s there.
Tradeoff
Webhooks eliminate polling overhead and provide near-instant notifications.
Yet they require exposing a public endpoint, handling retries when your server is down, securing the endpoint against unauthorized requests, and handling duplicate or out-of-order events.
The sender controls retry logic, and you can’t always guarantee delivery.
Why it matters
Integrating with payment providers like Stripe, receiving GitHub repository events, getting Slack notifications, building event-driven workflows, or any system needing real-time notifications from external services.
Essential for modern API integrations. Combine with message queues for reliable processing and idempotency for handling duplicates.
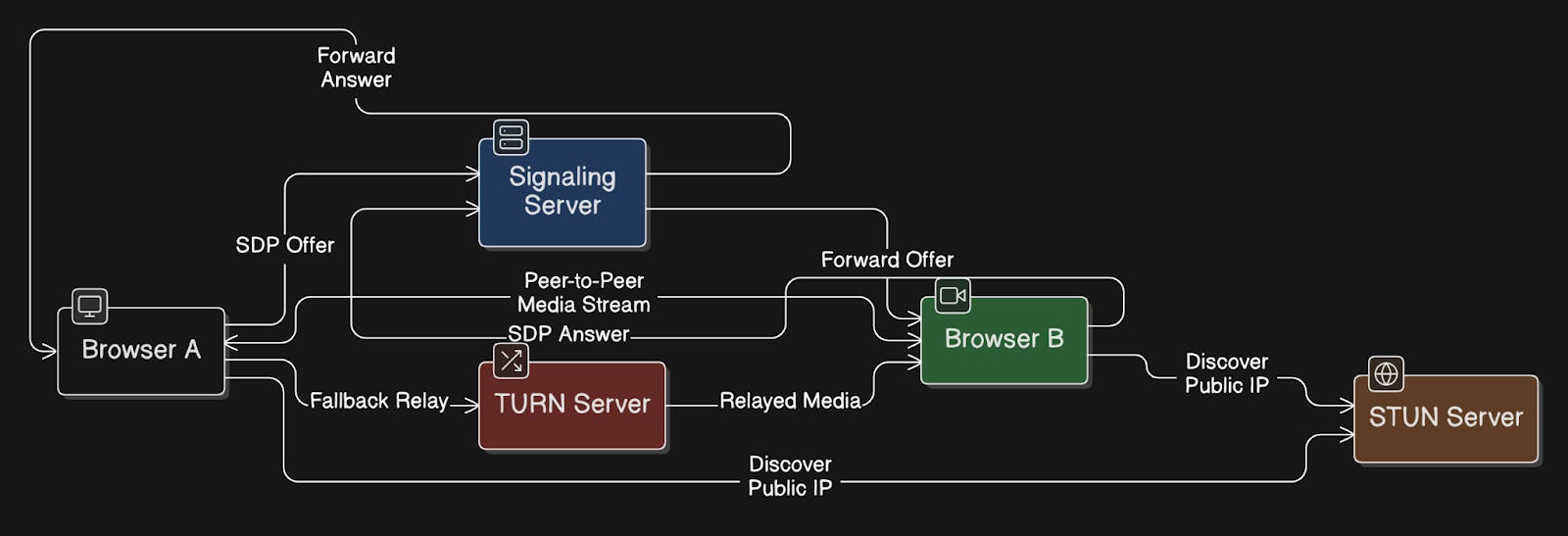
78. WebRTC
WebRTC (Web Real-Time Communication) is a technology that enables peer-to-peer1 audio, video, and data sharing directly between browsers without requiring servers to relay media.
After initial signaling through a server to establish the connection, media flows directly between peers.
WebRTC automatically handles:
Getting through NAT and firewalls
Encrypting the connection
Adjusting video quality based on network speed (adaptive bitrate streaming)
It’s built into modern browsers, so users don’t need to install plugins.
Analogy
It is like two people being introduced by a mutual friend:
The friend shares their phone number, but once they start talking, the friend is no longer on the call.
Tradeoff
WebRTC offers very low latency, thus making it ideal for live conversations. It can also reduce server costs because media often bypasses backend servers.
But:
It’s difficult to implement correctly
You usually need a TURN server as a backup when a direct connection cannot be made
Debugging network problems can be hard
Some corporate networks block peer-to-peer connections
Why it matters
WebRTC powers:
Video calls
Screen sharing
Voice chat in games
Live collaboration tools
It’s used in Zoom, Google Meet, and Discord.
If you’re building a real-time app, you can use WebRTC directly. But consider managed services like Twilio or Agora so you do not have to run your own signaling and TURN servers.
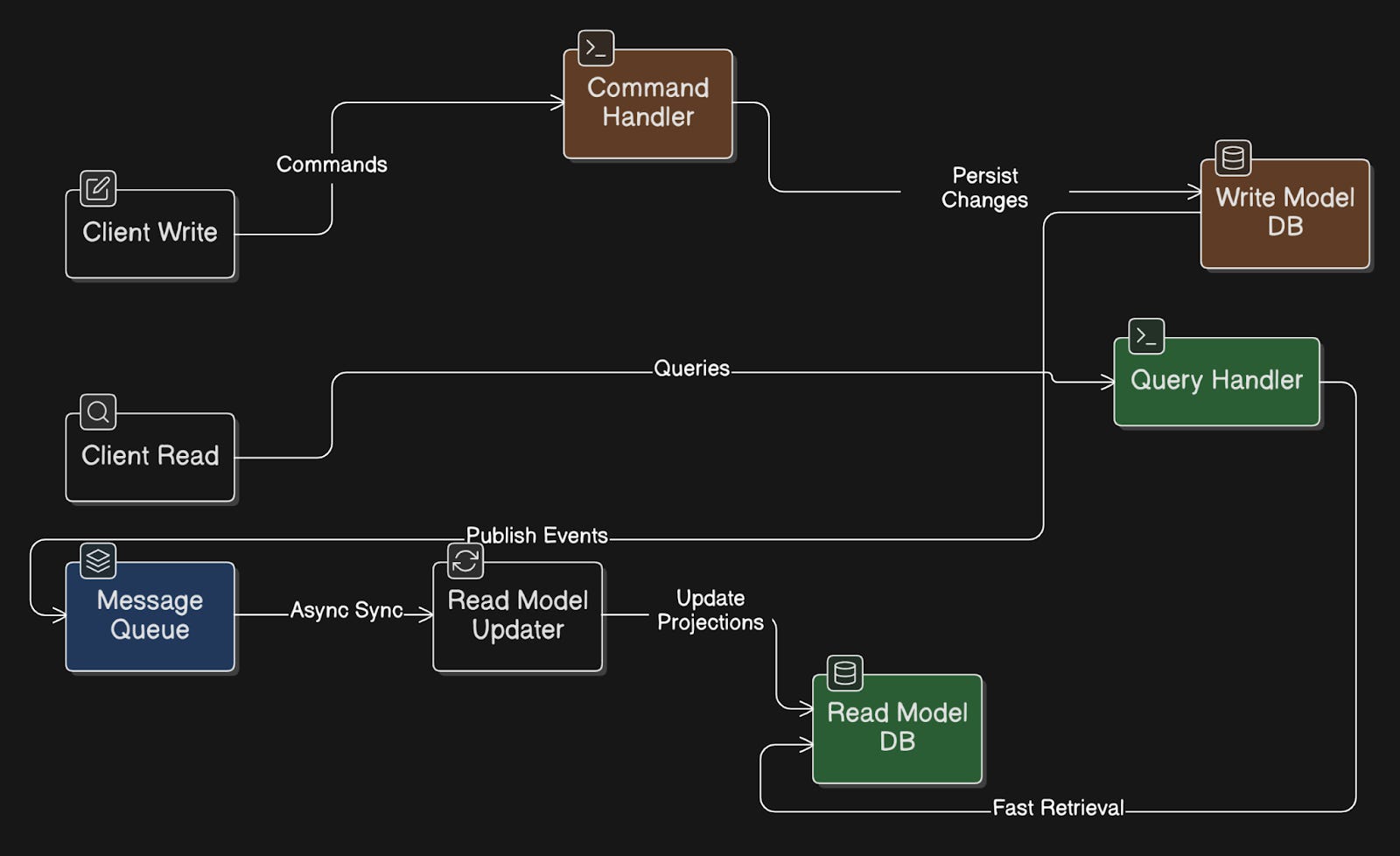
79. CQRS
CQRS (Command Query Responsibility Segregation) means separating how your system writes data from how it reads data.
Commands are used to change data. They use a write model optimized to handle updates.
Queries are used to read data. They go to a separate read model designed for fast retrieval.
The read model is often eventually consistent, updated asynchronously from the write model using events.
Analogy
Imagine a restaurant with two separate counters:
One counter takes orders... it focuses on taking them correctly. The other counter only handles pickups. It focuses on quickly delivering food to customers.
Both handle the same orders, but each serves a different purpose.
Tradeoff
Benefits:
Scale reads & writes separately
Design different data models for reading and writing
Create specialized read models from the same write model
Drawbacks:
Adds architectural complexity
Read side may not reflect changes immediately
Requires event handling or synchronization between models
Makes the system harder to understand and maintain
It is usually too complex for simple CRUD applications.
Why it matters
CQRS is useful when:
Your system has very different read & write workloads
Reads significantly outnumber writes
You need many views of the same data
Domain & business logic is complex
It’s often used together with Event Sourcing.
But a single model for both reads and writes is usually enough for simple systems.
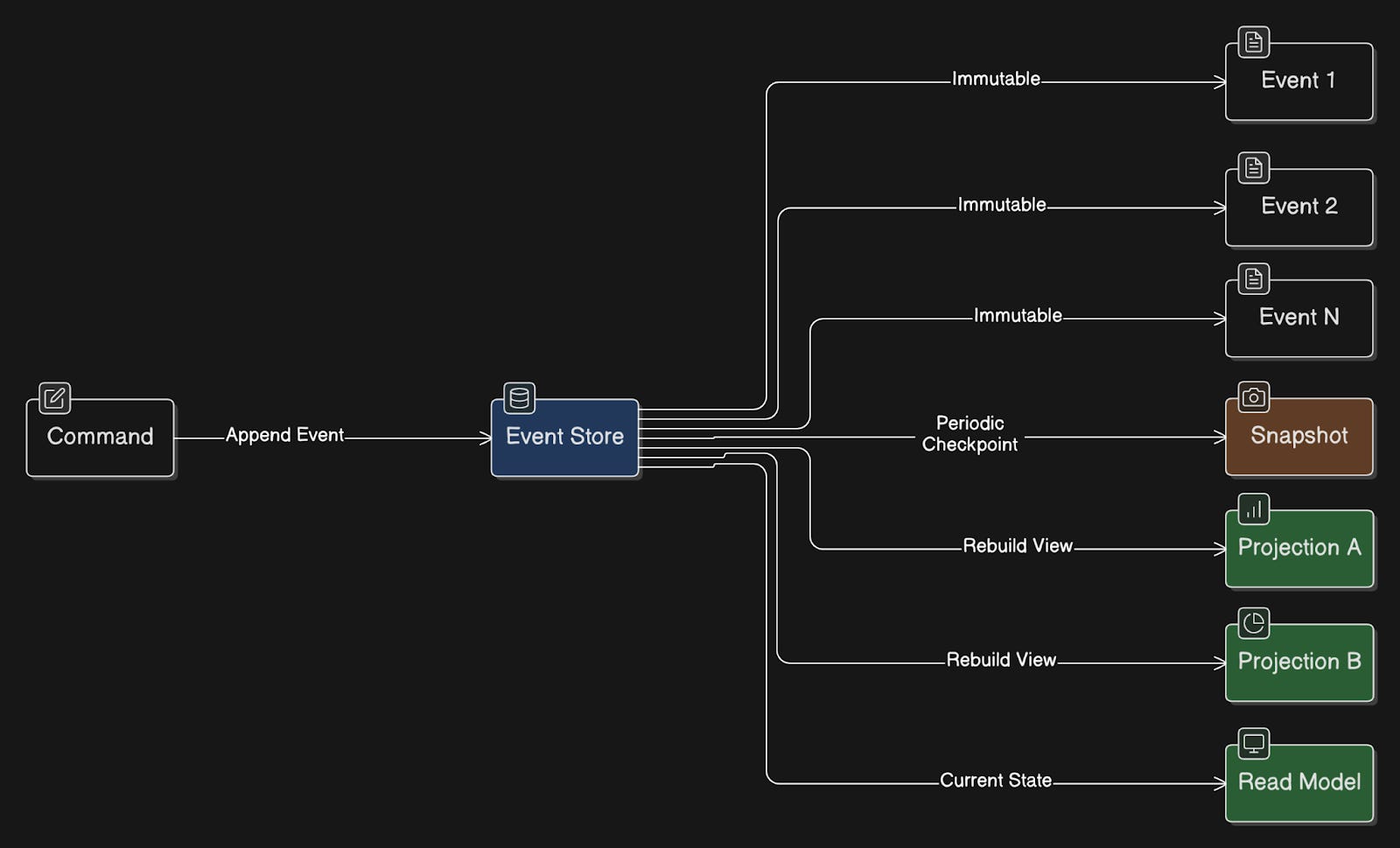
80. Event Sourcing
Event Sourcing is a way of storing data in which you record every change that happens in the system, rather than only saving the latest state.
Each change gets captured as an immutable event.
You can rebuild the current state by replaying events from the beginning or from a snapshot. You can also rebuild the state at any point in time and audit the complete history of changes.
Analogy
Think of a bank that records every transaction in a ledger:
Instead of only storing your current balance, bank keeps a list of all deposits and withdrawals. Your balance can always be calculated by adding up all those transactions.
Tradeoff
Benefits:
You get a history of all changes
Easy to audit what happened and when
You can rebuild the system state at any time
You can create new views or reports from past events
Drawbacks:
Harder to design & implement
Events are immutable, so fixing mistakes requires new corrective events
Getting the current state often requires projections or snapshots
Event formats may change over time, which makes schema evolution difficult
Event storage grows unbounded without snapshots
Why it matters
Audit-heavy domains such as financial systems
Systems that need historical queries
Systems that need many views built from the same data
It’s often used together with CQRS.
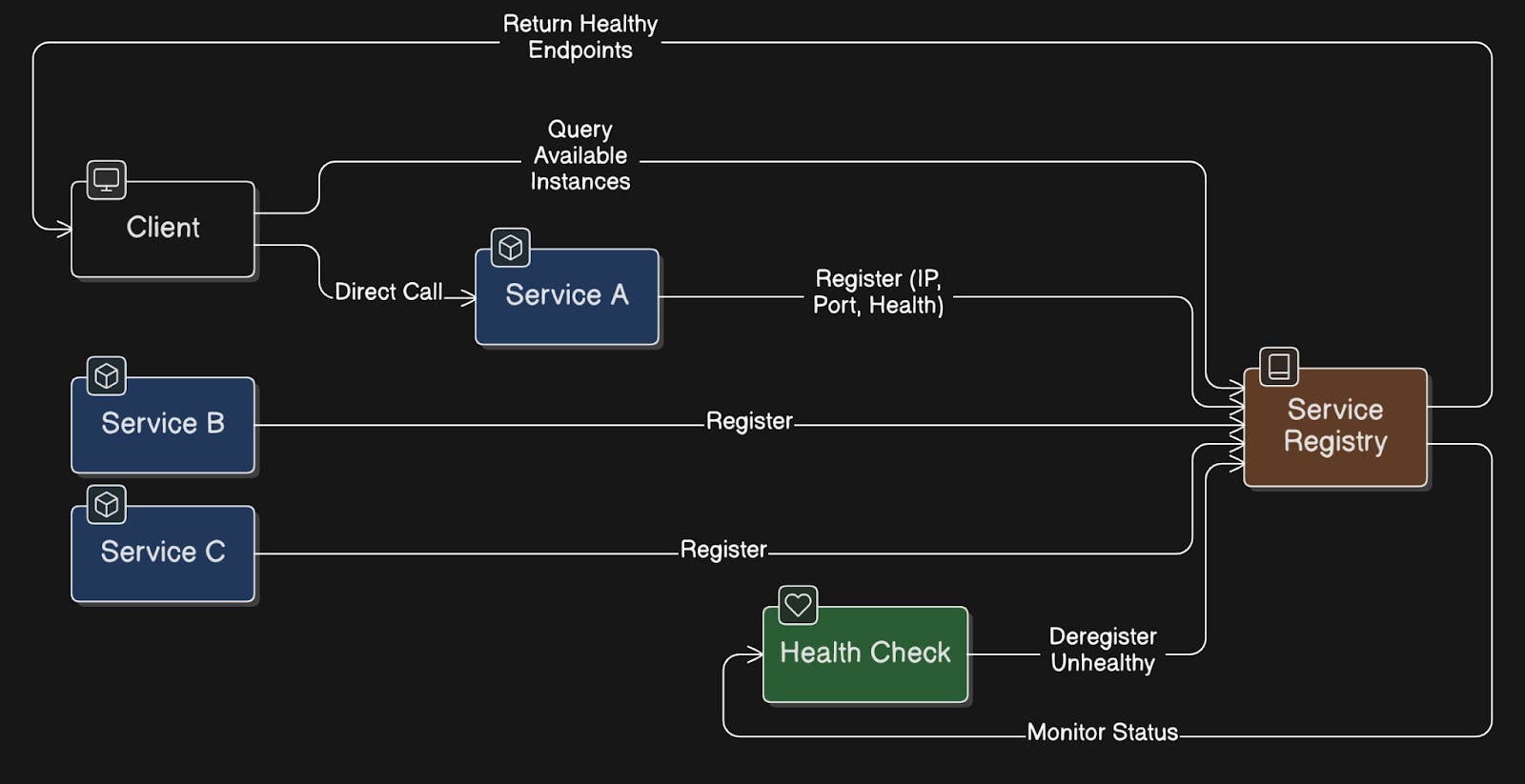
81. Service Discovery
Service discovery allows services within a system to automatically find and communicate with each other, eliminating the need for fixed IP addresses.
When a service starts, it registers itself in a service registry. The registry tracks where each service instance is running. When another service wants to call it, it asks the registry for the instances and connects to one of them.
Common tools: Consul, etcd, and Eureka.
Analogy
Think of it like a phone directory:
Instead of remembering everyone’s phone number, you look them up in the directory. If someone changes their number, the directory gets updated so people can still reach them.
Tradeoff
Requires health checks
Adds infrastructure complexity
It can become a critical dependency
Service lookups can add a small amount of latency
Cached results might sometimes point to instances that are no longer healthy
Why it matters
Service discovery is important in environments where services move or scale frequently:
Microservices architecture
Container platforms like Kubernetes
Cloud systems with auto-scaling
It allows services to locate and communicate with each other even when their IP addresses or instances change dynamically.
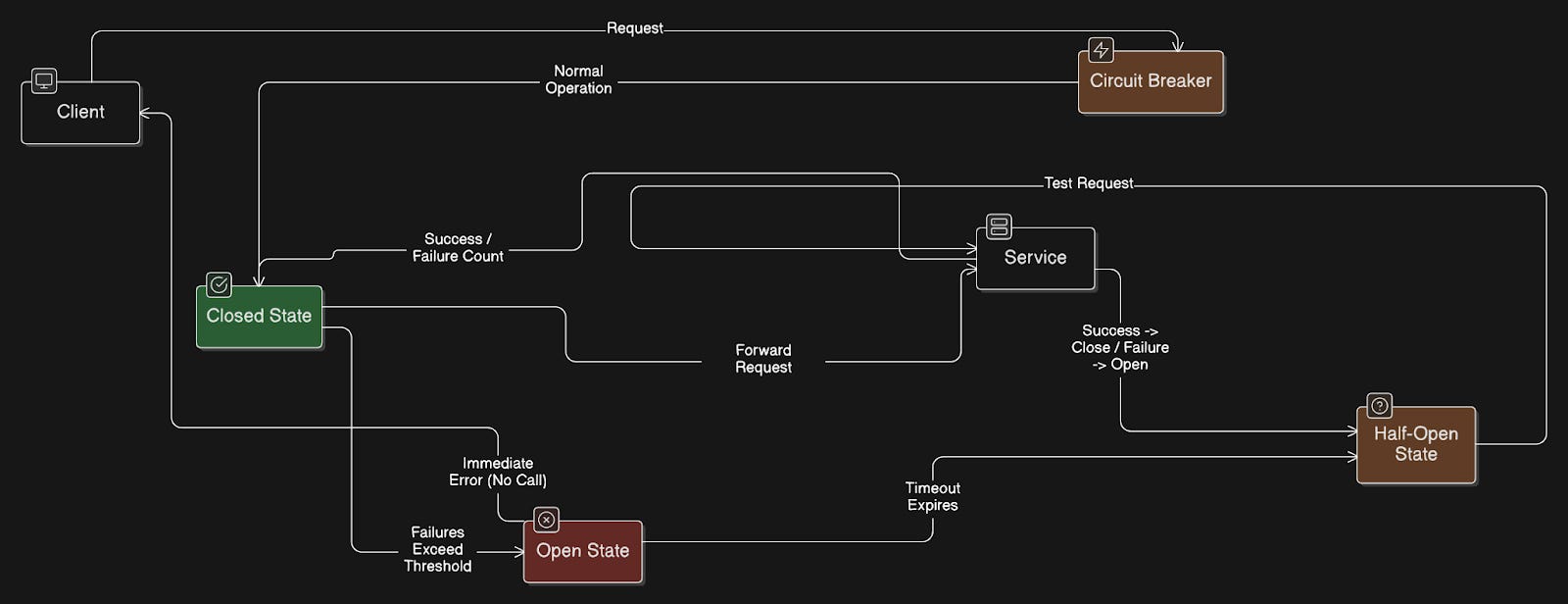
82. Circuit Breaker Pattern
Circuit breaker pattern protects a system from repeatedly calling a failing service.
A circuit breaker sits between a service and the dependency it calls (for example, another service, API, or database). It monitors failures such as errors or timeouts.
If failures pass a threshold, the circuit breaker “opens” and stops sending requests to the failing service. Instead, it immediately returns an error or a fallback response.
After a set time, the circuit breaker moves to a “half-open” state. It allows a small number of test requests.
If those succeed, the circuit “closes” and normal traffic resumes.
If they fail, the circuit “opens” again.
Analogy
It works like an electrical circuit breaker in a house:
If too much current flows, the breaker cuts power to prevent damage. After the problem gets fixed, you reset the breaker and power flows again.
Tradeoff
Benefits:
Prevents cascading failures in distributed systems
Reduces load on failing services so they can recover
Fails fast instead of waiting for long timeouts
Protects system resources
Drawbacks:
Adds complexity to service calls
Requires tuning thresholds & timeout values
Can open unnecessarily if thresholds are set incorrectly
Needs monitoring to detect when circuits are open
Why it matters
It’s useful when systems make network calls that can fail, such as:
Microservices calling other services
Services calling external APIs
Systems that depend on remote databases or infrastructure
It helps prevent one failing dependency from causing failures across the entire system.
Common libraries: Resilience4j & Polly.
Reminder: this is a teaser of the subscriber-only post, exclusive to my golden members.
When you upgrade, you’ll get:
Full access to system design case studies
FREE access to (coming) Design, Build, Scale newsletter series
FREE access to (coming) popular interview question breakdowns
And more!
Get 10x the results you currently get with 1/10th the time, energy & effort.
Keep reading with a 7-day free trial
Subscribe to The System Design Newsletter to keep reading this post and get 7 days of free access to the full post archives.