
30 Core Agentic Engineering Concepts, Explained Simply
#154: What an agent is, how to configure one, when to use multiple, and how to keep them from doing damage.


Share this post & I'll send you some rewards for the referrals.
How do you keep up with agentic engineering when a new tool ships every week?
You do not…
You learn the ideas behind the tools, and let the tools come and go.
The pace will not slow down. New models, new frameworks, a new “this changes everything” launch every few days. Chase all of it, and you spend more time switching tools than using them.
But underneath the noise, it is the same few ideas every time.
One calls it a skill, the next calls it a rule; it's the same job underneath.
Learn the idea, and it stops mattering which tool you pick.
By the end of this newsletter, you can read any agent post or news drop and see which of these ideas it actually covers, instead of feeling behind every time something new ships.
Onward.
”How to adopt externalized authorization: step-by-step roadmap” eBook by Cerbos (Sponsor)

Hardcoded authorization logic doesn’t scale. As systems grow and requirements change, those tightly coupled permissions end up slowing down development, creating security risks, and making compliance a nightmare.
This 80-page eBook breaks down how hundreds of engineering teams have tackled this problem. It walks through the practical steps for moving from hardcoded permissions to externalized authorization.
What’s in it:
Step-by-step adoption strategy from planning to PoC rollout
Frameworks, policy examples, code samples
Lessons from teams who’ve made the transition
If you’re dealing with authorization complexity, this might save you some of the trial and error.
(Thanks to Cerbos for partnering on this post.)
I want to introduce Paul Hoekstra as the guest author.

Paul is a data engineer at Digital Power, a data and AI consultancy, and writes Paul’s Pipeline, a free newsletter on AI, data, and side projects.
This newsletter pulls out the ideas that keep mattering, whichever tool you pick. If it leaves you wanting more, he has a four-part series on the layers covered in this newsletter: configuration, capability, orchestration, and guardrails.
Here’s what you’ll find inside this newsletter:

Foundations. What an agent is, how it runs, where its state lives, and the patterns you build once you have more than one.
Configuration. How you shape the agent’s behavior before it writes a line of code: config files, reusable workflows, prompt caching, and the context rot that limits all of it.
Capability. What the agent can reach for once it is running: live documentation, AI-native search, long-term memory, and knowledge it queries but never owns.
Orchestration. How you coordinate multiple agents without letting them step on each other.
Guardrails. What stops the agents from doing damage: sandboxing, permissions, hooks, and the commit gates that catch the rest.
Observability. How you see what an agent actually did after it stopped typing: tracing, logging, replay, and metrics.
Foundations
Let’s dive in!
1. What is an agent?
“Agent” gets used for almost anything these days.
Let us pin it down:
An agent is a large language model (LLM) that runs in a loop, has access to tools1, and decides what to do next. Instead of a single answer to a prompt, the model produces a chain of actions. And each action builds on the result of the last.
Coding is the most obvious use case so far.
The loop fits naturally there. Small building blocks. Fast feedback from tests and errors. Files the agent can edit directly. The same shape works for research agents, ops automation, customer support, and content workflows.
Use an agent when:
Task is open-ended (”debug this failing test”, not “format this date”)
The next step depends on the result of the last one
You cannot script the path in advance
But skip the agent when a single prompt or a plain script will do.
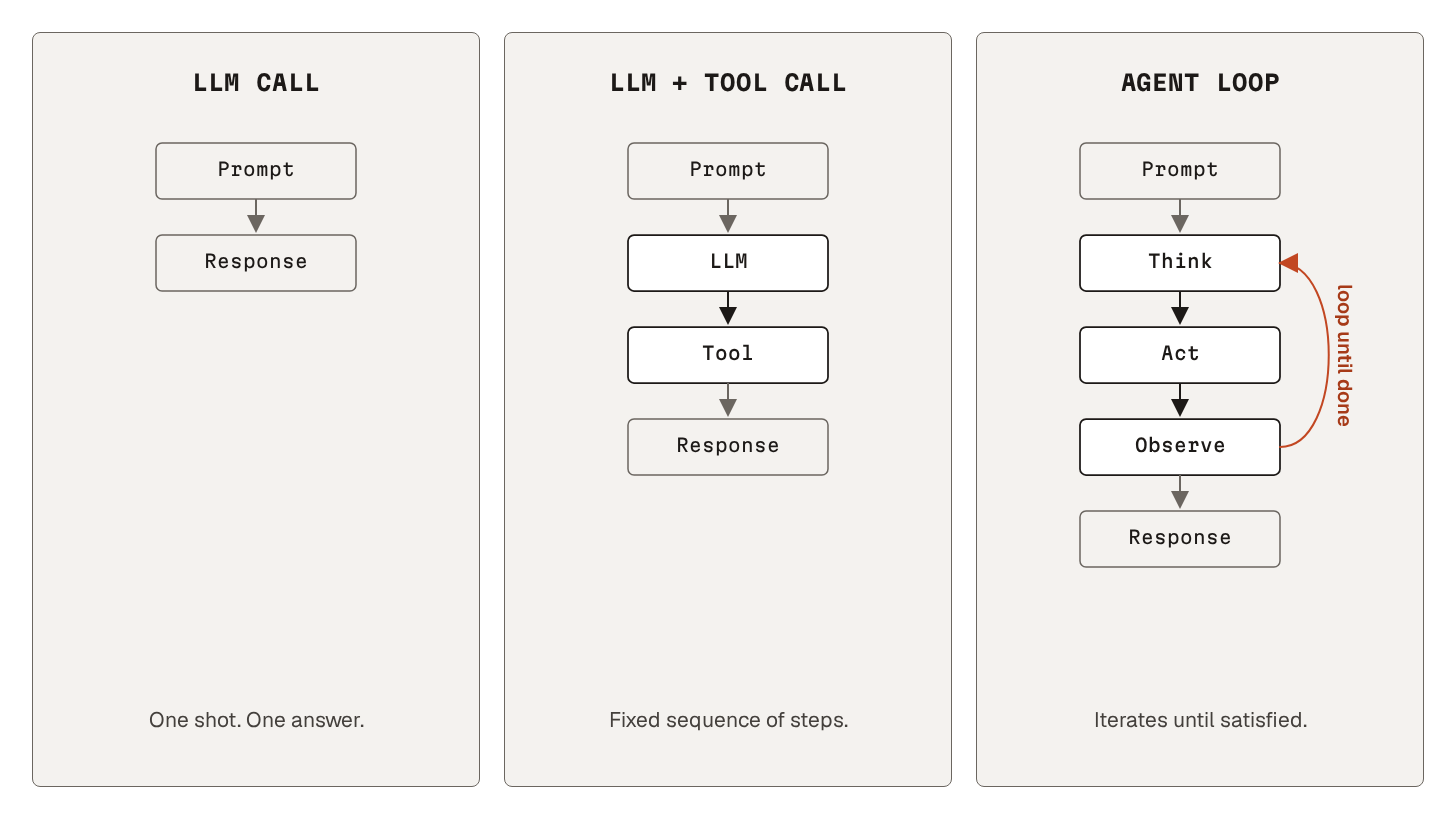
Loops are not free.
Every time round the loop costs time and money, and they add up fast. The agent gets less predictable. And it gets harder to debug: the runs are longer, and the agent does not always make the same choices twice.
You do not have to pick one mode for everything.
Use a single prompt or a plain script for easy problems. Reserve the agent for tasks where its flexibility earns the cost.
2. Execution model
An agent loop has a recognizable shape.
Three steps, repeated until something says we are done:
First, the model thinks. It reads the current state of the conversation and decides what to do next.
The model then acts. It emits a tool call. The harness2 around the model receives the call, validates it, and runs it: file read, shell command, MCP request, whatever fits.
Finally, the model observes. The tool result joins the conversation as new context. The next iteration starts with that result in scope.
This pattern goes by a few names.
ReAct (from the original paper), Think-act-observe, agent loop.
The name changes, but the loop does not.
A single model call has to predict the entire path up front and commit to it. The loop replaces that prediction with feedback. The model takes one step, observes what actually happened, and decides the next step based on the actual result rather than a guess.
This is why an agent can recover from its own mistakes.
A failing test returns a stack trace. A blocked command returns an error. Each one is just the next observation, and the next iteration plans against it. The loop catches a wrong first step on the next pass, instead of letting it poison everything after it.
Two variations sit on top of this basic loop:
Parallelism. Modern agents can fire several tool calls inside a single act step. That cuts wall-clock time on read-heavy work. It also causes conflicts when two parallel calls try to edit the same thing. We will come back to ways of handling that when we get to subagents (concept 17).
Blocking vs non-blocking. Most agents run synchronously: conversation waits while a tool runs, then the result comes back as the observation. Some run asynchronously and fire off long-running jobs in the background. Async unlocks fan-out, at the cost of more complexity.
3. Agent state
“State” gets used in two senses.
One is workflow progress: which step the agent is on and what is left. Agent loops carry that sense across iterations (concept 17). This concept is the other sense: everything the agent knows at any moment.
It breaks into two halves with very different properties:
Context window: everything the model can see right now. Your latest message, the system prompt, the agent’s previous tool calls, and the results of those calls. It has a hard ceiling (the token cap) and a soft one (concept 9, context rot). When a session ends, the context window is gone.
Everything outside it: what the model cannot see until it fetches it. Files on disk, database entries. Memory that survives across sessions (concept 14). Knowledge the agent only queries and never owns (concept 15). The model cannot reason over any of it directly, but the agent can pull pieces into context on demand.
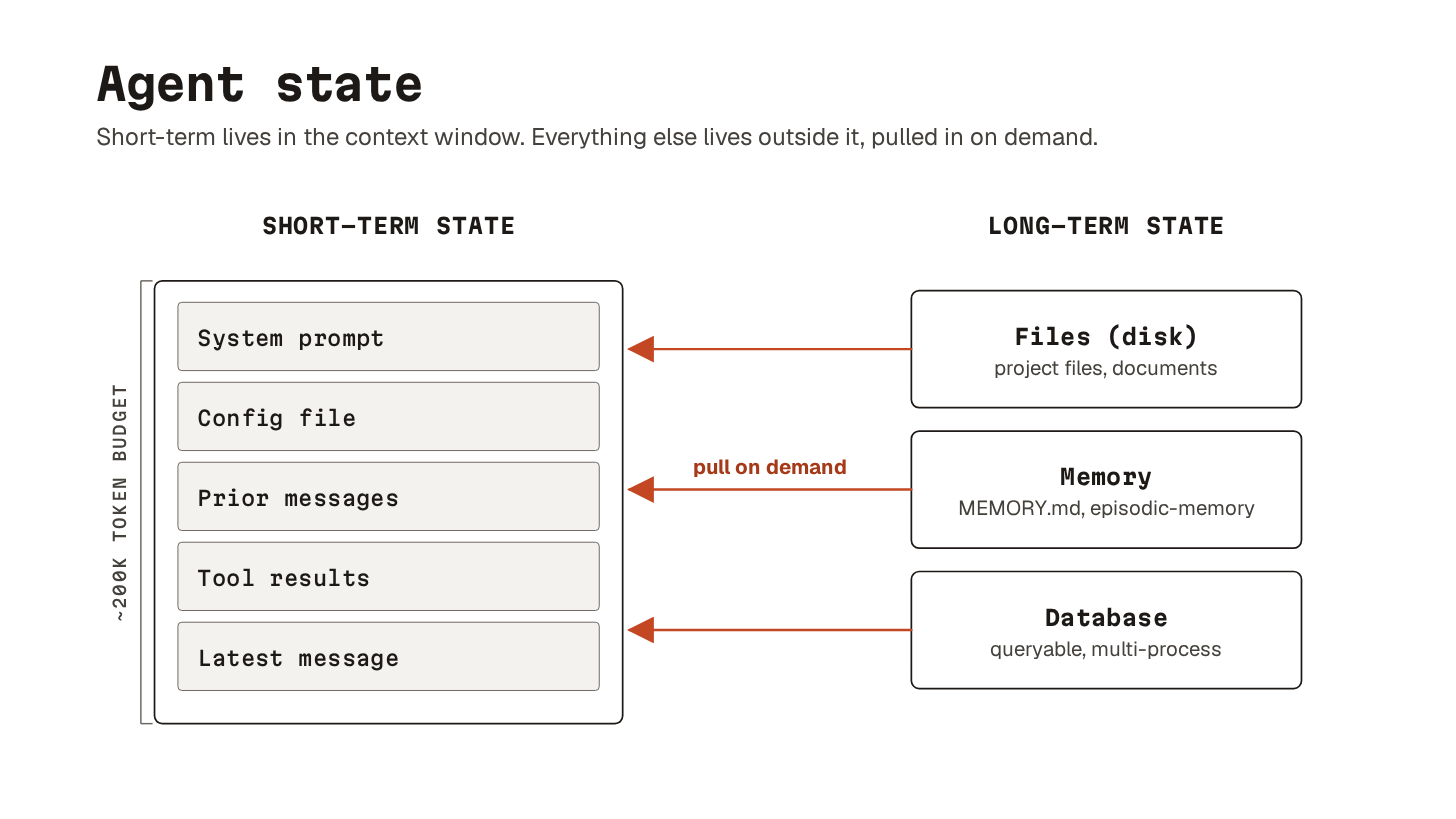
So, where should your state actually live?
Files are usually the right default. They are diffable, versionable, and easy for both you and the agent to edit. Memory works well for facts that survive across sessions but do not need git history. Databases earn their place when the state needs to be queried by structure or shared across processes.
Multiple agents make the state harder.
Two agents reading the same file is fine. Two agents writing to it is the canonical race condition. Git worktrees (concept 16) give each agent its own working copy.
Subagents are friendlier: each starts with a fresh context window, and the parent passes in only what it needs. If the parent has to pass more than a few paragraphs, the split between the two is probably wrong.
4. Common agent patterns
Once you have multiple agents to work with, the question is how to compose them.
There are a handful of useful patterns to know:
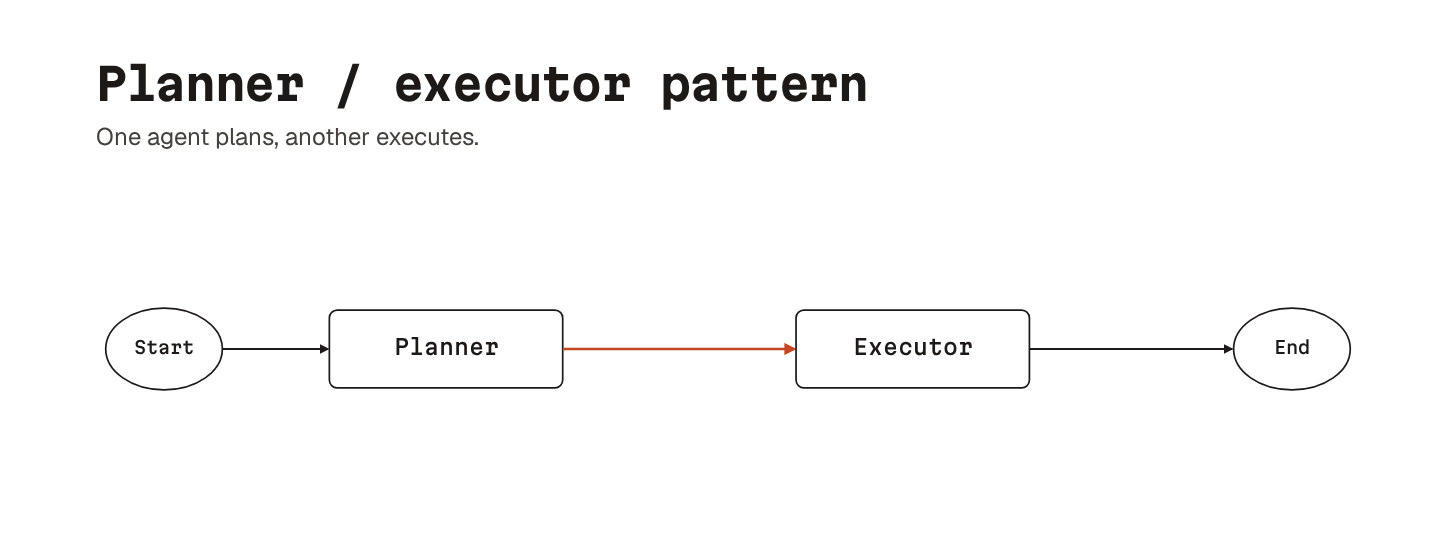
The simplest is planner/executor.
One agent plans, another executes. The split keeps each agent in a context shape that suits it: open-ended thinking on one side, tight execution on the other. Useful for long tasks where you want planning quality separate from how the implementation goes.
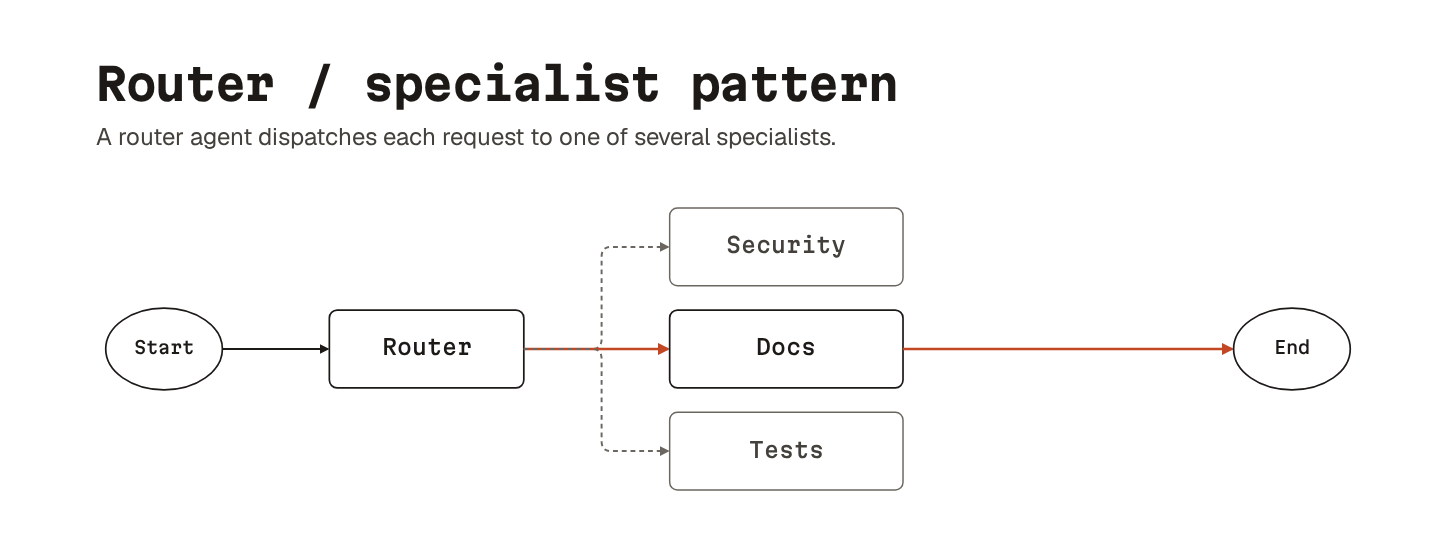
Router/specialist sits one level above.
A router agent takes the incoming request and dispatches it to one of several specialists. Each specialist has a tighter system prompt and a smaller toolset: a security reviewer, a debug specialist, a docs writer, a test author. Cheaper, because most calls hit a smaller model. Easier to reason about, because each specialist’s behavior is bounded.
Map-reduce parallelism is the workhorse for read-heavy fan-out.
Send a single task out across many subagents and merge their results. “Review this pull request” splits into one subagent per file, and the results merge into a single summary. Cost is bounded by the longest individual subagent. Quality is bounded by how well the aggregator merges.
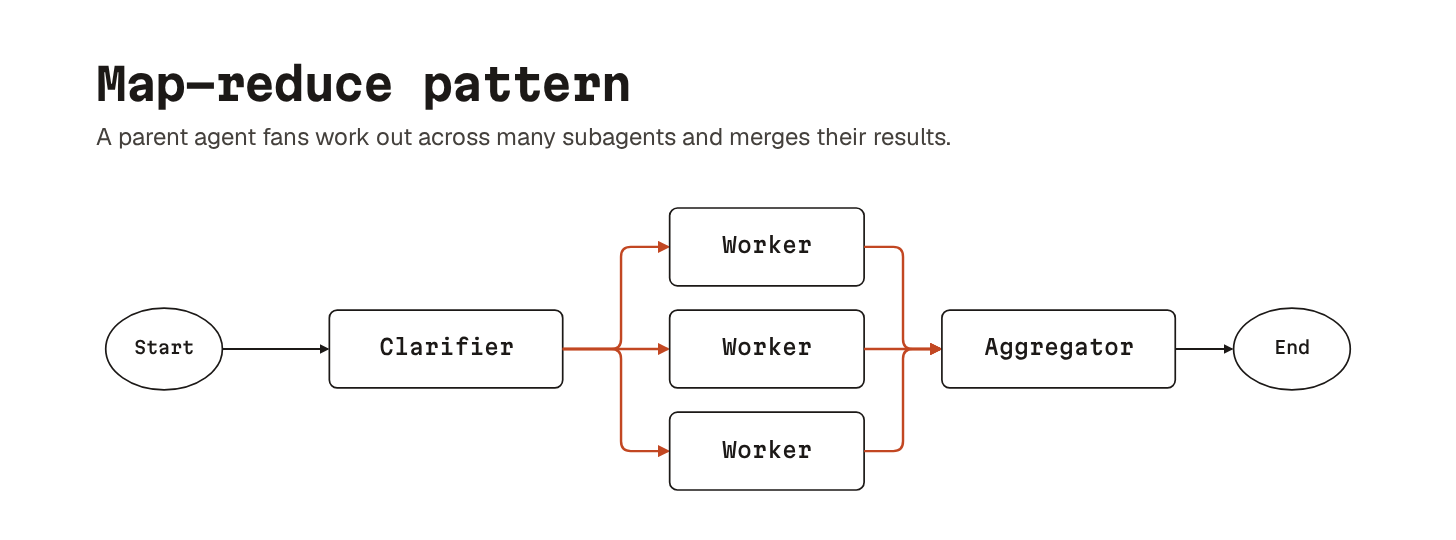
These patterns are not exclusive.
Real workflows combine them: a planner spawns a router, the router fans out work map-reduce style, and the merged result comes back for review.
Every pattern relies on handoffs between agents.
Each handoff carries a compressed summary, so the next agent does not start from scratch. That is what makes the patterns useful: they define where one agent’s job ends and the next one’s begins. Those seams are where work tends to break.
That’s the foundation done.
Next come the four practical layers, starting with how you shape the agent’s behavior before it touches any code.
Configuration Layer
Let’s dive in!
5. Agent config files
Every agent starts with a system prompt.
The harness builder bakes in a block of instructions that covers tool use and the harness’s own conventions. The system prompt does not know anything about your project.
Agent config files are the layer above.
The agent loads a project-level Markdown file at the start of every session, and the file remains in the context window for each subsequent step. The file tells the agent your standards, limits, conventions, and behavioral rules.
Claude Code calls this file CLAUDE.md.
Most other tools have settled on AGENTS.md. A bit like Apple and USB-C: the industry wants a standard, but not everyone follows it.
It matters because agents default to whatever looked most plausible in their training data. Without a config file, you get pip install when your project uses uv, black when you use ruff, and defensive sludge wrapped around every change.
With one, the agent reads a set of hard rules before it writes a line of code.
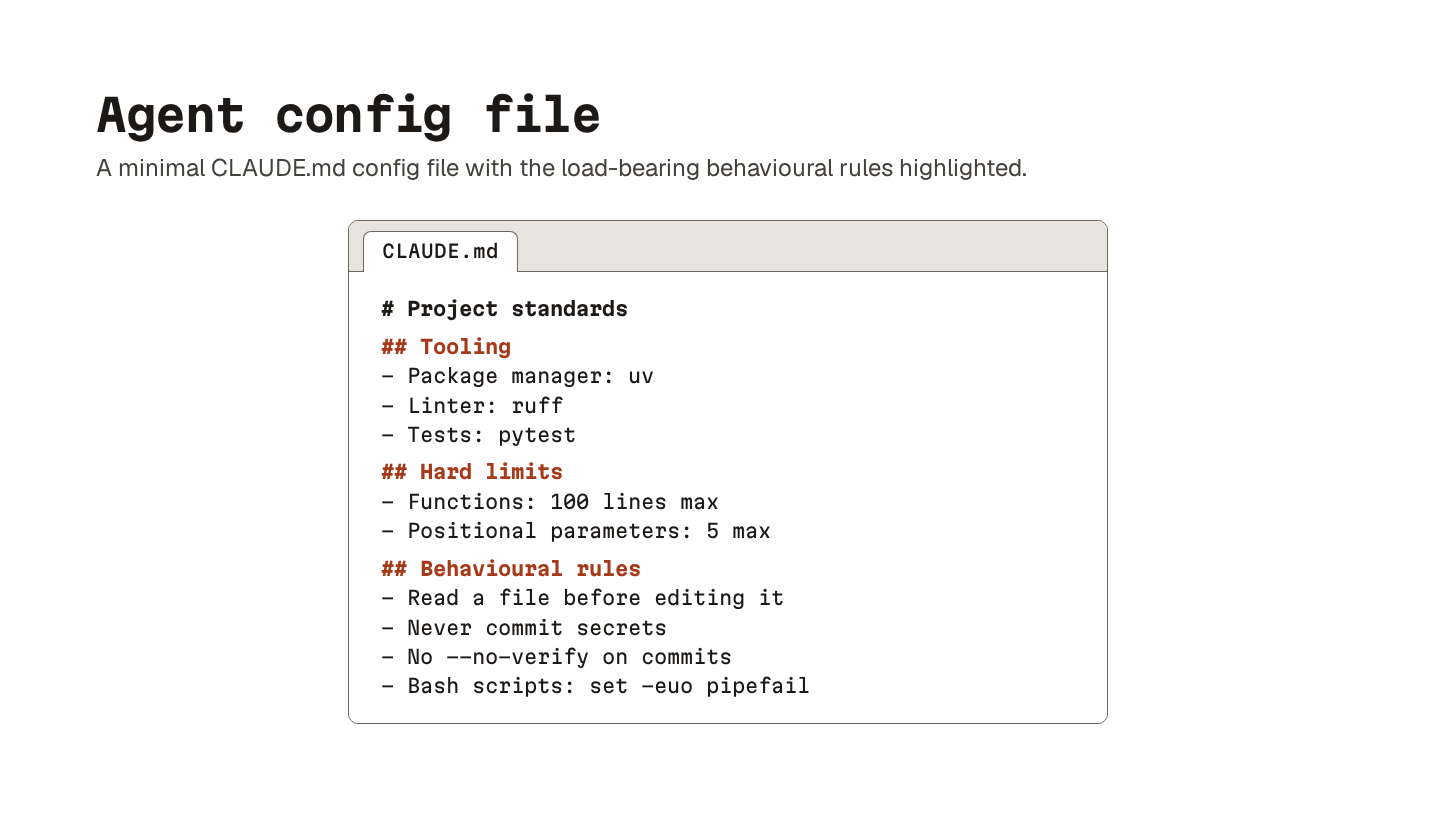
A useful config is short and specific:
Hard limits on function length
The package manager and tooling stack you actually use
A few behavioral rules like “never commit secrets” or “always read a file before editing it.”
Anything generic or AI-generated dilutes the file and makes the rest harder for the model to attend to.
Keep it under 100 lines. Cut anything that is not consistently improving outcomes. Treat it the way you would treat a Makefile: as code, not documentation, reviewed when it changes.
6. Reusable workflow files
If config files are always on, reusable workflow files are on demand.
They are still just Markdown, but with YAML frontmatter that controls when the agent loads them. Examples are Claude Code skills (in .claude/skills/) and Cursor rules.
The frontmatter3 does most of the work. A name and description tell the agent when the skill is relevant. An optional globs field narrows it further by file type or path pattern. Whether the skill actually helps depends on the quality of the instructions inside it.
Researchers built SkillsBench, a benchmark of 86 tasks across 11 domains, and provided models with brief written workflows for approaching each task.
Claude Haiku scored 27.7% with human-curated skills. That beat the 22.0% Opus scored without them. The cheapest model with good instructions outperformed the flagship without.
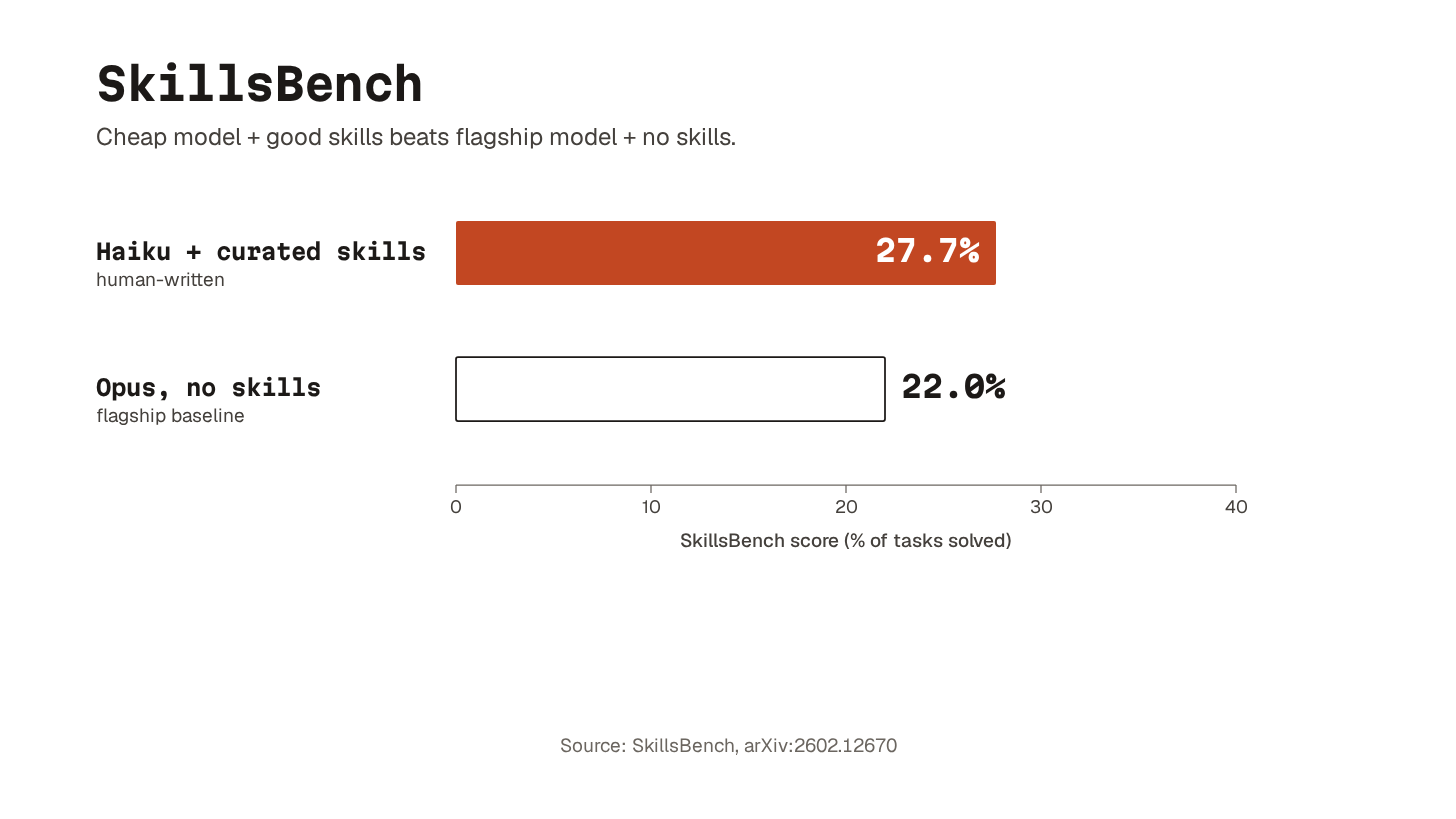
There is a second lesson in the data.
When the researchers let the model write its own skills, the gains disappeared. Given everything we know about context rot, that should surprise no one. Generic AI-generated boilerplate makes things worse, not better.
The rough division of labor is simple: config files for always-relevant project rules, skills for reusable task-specific procedures.
The live prompt for what is unique about the current task.
7. Workflow frameworks
If you are using an agent for coding, a framework on top helps.
The agent follows a documented process for planning, test-driven development (TDD), debugging, and code review. No more falling back on whatever it remembers from training. The mechanism is a chain of skills, hooks, and slash commands4 wired together into a repeatable process.
Here are a few options worth knowing:
Superpowers ships a curated library of skills for common workflows: brainstorming, TDD, debugging, and code review. It also adds
HARD-GATEdirectives and anti-rationalization tables. These push the agent to use the skills rather than skip them.
Get Shit Done does something similar, but through slash commands, hooks, and meta-prompting instead of skills.
Compound Engineering splits work into Plan, Work, Review, and Compound phases. The last phase captures patterns and solutions into a searchable knowledge base, so each feature makes the next one easier.
They differ in shape but share a thread: get the agent to understand what it is building, tell it how to go to work, and check the result against what you actually wanted.
8. Prompt caching
Prompt caching stores the stable prefix of the conversation so the model does not pay the full price to re-read it every turn.
Most agentic tools handle this in the background, but it is worth understanding because it changes the economics of long config files.
The mechanism is the same across providers:
The first call sends the full prefix, including the config file and any reusable workflows the agent has loaded, and pays a small premium to write that prefix into the cache. Later turns re-read it at a steep discount. Latency improves, too, because the model does not reprocess the same tokens.
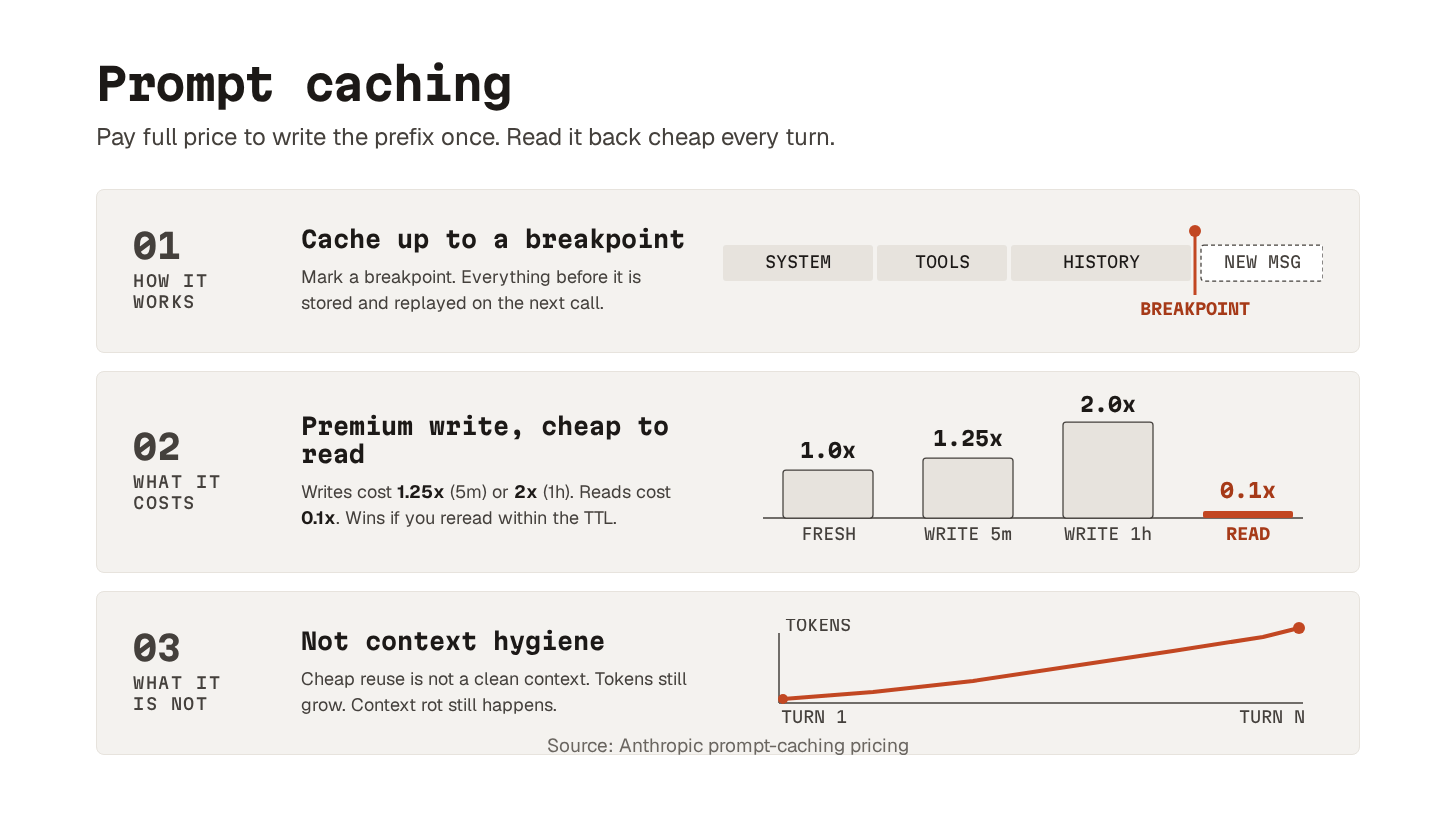
The catch is the cache time to live (TTL).
Caches expire after a period of inactivity, somewhere between a few minutes and an hour, depending on the provider. An active session keeps the cache warm. A long pause (coffee, Slack, a spec to read) lets it expire and forces a rewrite on the next call.
If your tooling lets you configure the TTL, longer windows cost more to write but stay warm through bigger gaps in activity. The choice depends on how active you expect to be. Longer TTL when you will keep coming back. Shorter TTL when you might not.
Without prompt caching, you would think carefully about the size of your config file. With it, the cost is closer to a rounding error.
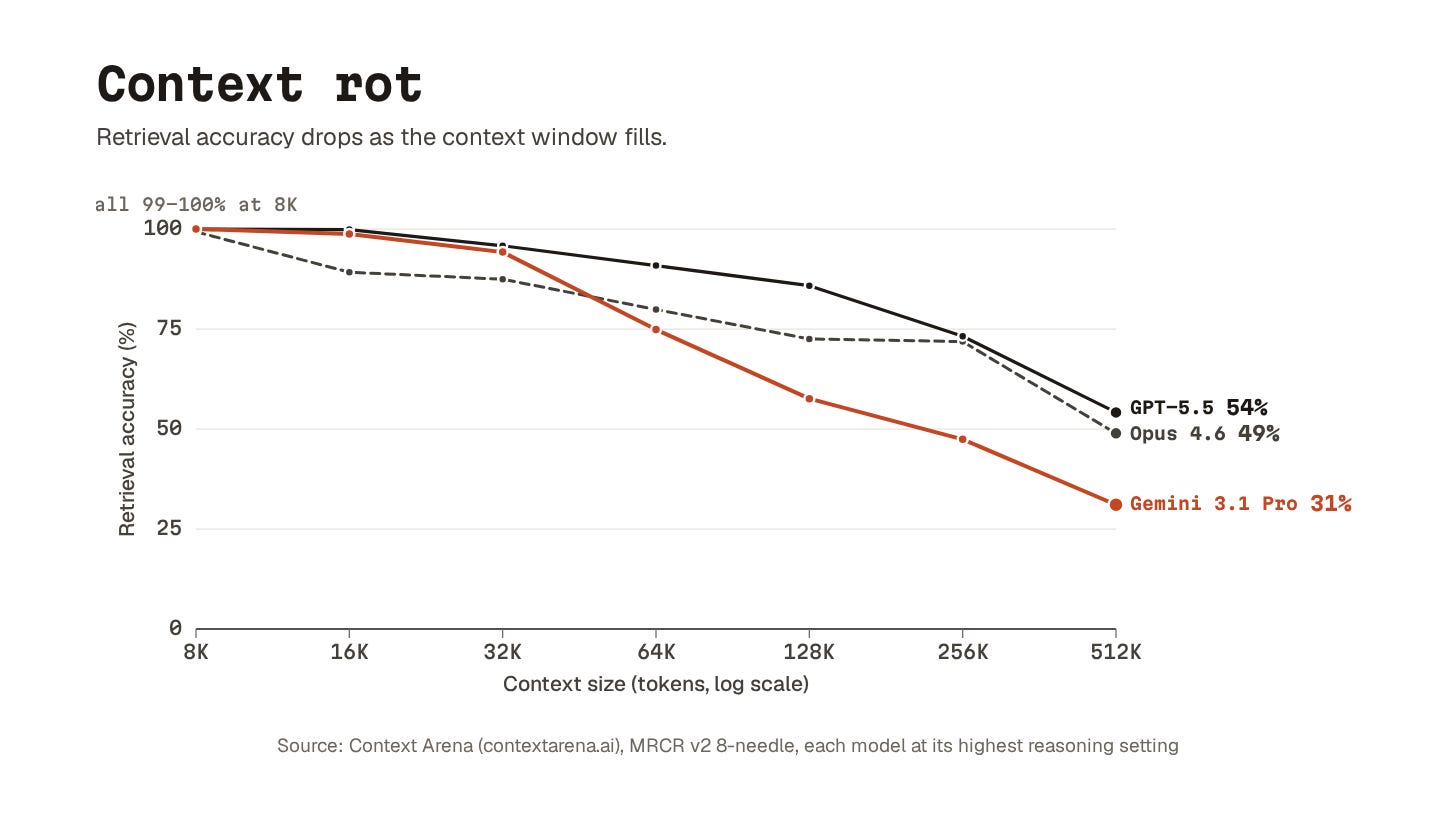
9. Context rot
Model performance drops as the context window fills up.
Prompt caching saves your wallet, but those tokens still sit there, and the model has to look past each one to get to what you want it to focus on.
Even the latest models show this:
Drop a few specific facts into a long document and ask a model to find them. GPT-5.5 scores 98.1% on short documents and 74.0% on documents stretching to a million tokens.
Claude Opus 4.7 drops from 59.2% at 256K to 32.2% at 1M.
A recent study confirmed the same effect for instruction quality. Stuffing the system prompt with generic AI-generated boilerplate produced worse results than having no file at all.
Transformers5 work by having every token attend to every other token in the context. Each token’s “attention” is a weighted distribution across the rest, with the weights summing to one.
Double the context, and each token’s share of that weight roughly halves. The model splits its finite attention budget across more material. The relevant signal gets diluted by everything around it.
There is a training distribution effect on top of that.
Most of what these models learned from is short. Behavior in very long contexts is partly extrapolation. Retrieval drops the further you push from the lengths the model trained on most.
The takeaway runs through every other concept in this layer.
Config files, skills, MCPs, even memory: every token competes with everything else for the model’s attention. Keep the things you need lean. Cut anything that is not pulling its weight.
That covers configuration. Now we look at what the agent can actually reach for once it starts running.
AI research is easy—verification is hard (Partner)

Most AI research agents can find information.
The harder problem is correctness — whether an answer is actually right, not just well-formed.
Many systems reason, search, and verify within the same context window. When they make mistakes, they often review their own work using the same signals that produced the error. This creates a subtle failure mode: outputs can look consistent, pass internal checks, and still be wrong.
Apodex refers to this as pseudo-correctness — answers that appear valid under the model’s own evaluation, but do not actually solve the underlying problem.
Apodex is built differently.
As a Self-Evolving Heavy-Duty Solver, it separates generation from verification. Specialist agents build solutions from evidence, while independent verifier agents audit the result before it is finalized.
Instead of asking whether an answer “looks correct,” Apodex evaluates whether it actually holds. Verification is structured across three axes:
Comprehension — did it capture the real problem?
Causality — does it address the true cause?
Empirical grounding — is it validated through execution?
This shifts verification from self-review to independent audit, reducing pseudo-correctness at the system level.
On LiveCodeBench v6, the heavy-duty configuration improves a 397B model from 82.0 to 85.1 under identical parameters, driven primarily by the verifier layer. It also achieves 79.0 on SWE-bench Verified and 58.4 on Terminal-Bench v2.
The Apodex 1.0 release includes Apodex-1.0-H, Apodex-mini, AgentOS, and open-weight models at 0.8B, 2B, and 4B.
See how verified AI research works:
For developers who want to dive deeper:
Capability Layer
Let’s keep going!
10. Model Context Protocol (MCP)
MCP is a standard for giving agents access to external tools and services.
Originally an Anthropic spec, now broadly adopted across the ecosystem. Here’s the basic idea: a tool exposes itself through a protocol the agent already understands, so you stop hand-rolling glue code per tool and per agent.
Yet MCP gets a lot of heat.
The basic criticism is that it is redundant and slurps context. Why add a new protocol when agents can already use command-line interfaces (CLIs), scripts, and direct API calls?
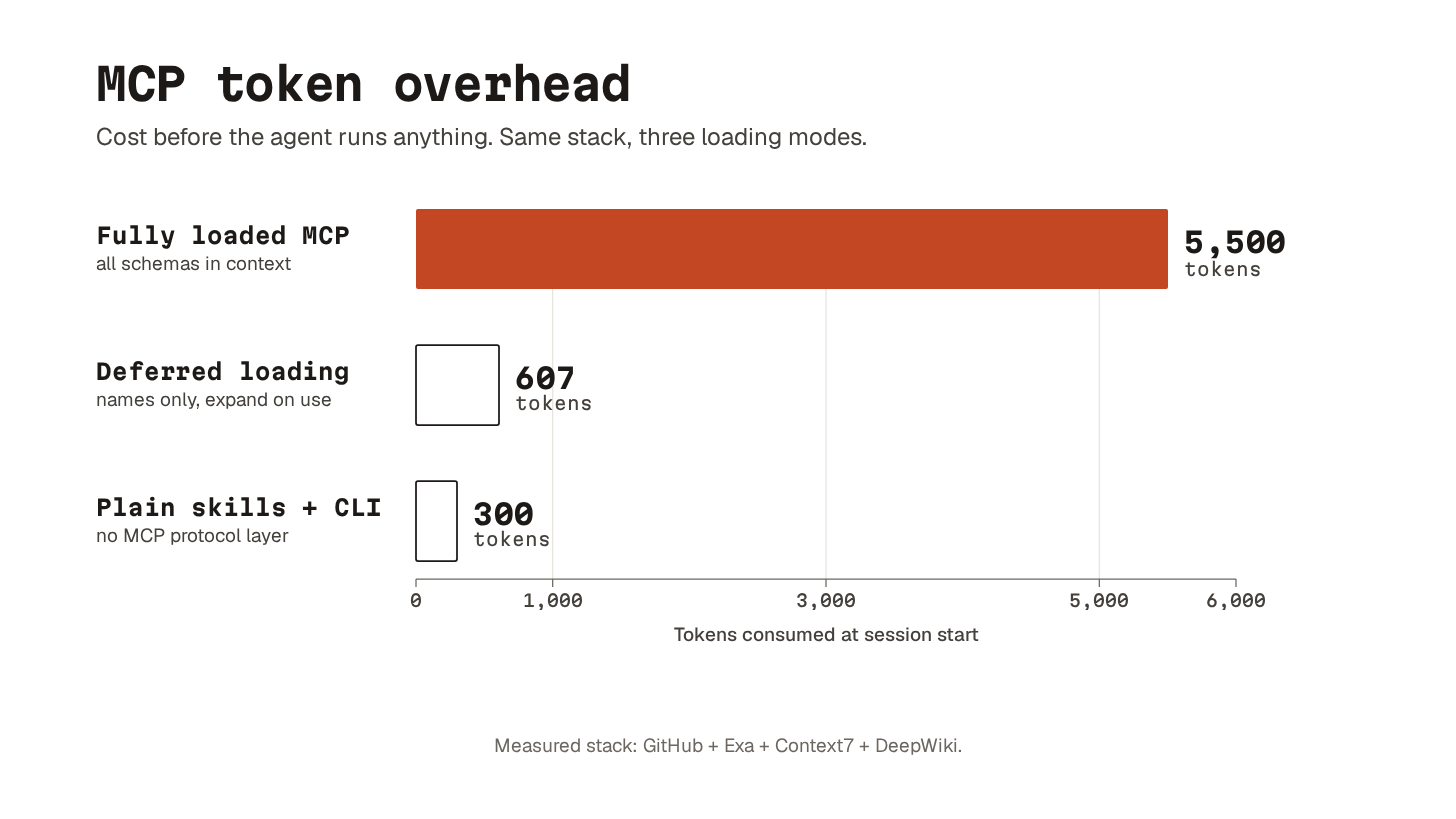
A fully loaded MCP is expensive.
By 2026, deferred tool loading is the norm. The agent starts with a list of tool names and descriptions. The full schema only loads when the agent decides to use a tool. With deferred loading, a stack like GitHub + Exa + Context7 + DeepWiki costs about 607 tokens before any tools are used. The fully loaded version costs around 5,500. A few plain skills calling CLIs directly cost about 300.
So MCPs are still heavier than the leanest alternative.
But they solve real problems: standardization, auth, permissions, organizational distribution. And they are getting leaner. Whether MCP itself is the protocol that wins is a separate question.
11. Live document retrieval
Models have knowledge cutoffs.
When the agent does not know an API signature, it usually does not say so. It guesses... confidently. And because the guess looks plausible, you only catch the mistake at runtime.
Context7 pulls live library docs into the agent’s context.
The agent gets current documentation and working examples. Not whatever version was in the training data. This wipes out an entire class of bugs where it confidently calls functions that have been renamed, moved, or deprecated.
DeepWiki goes one level out.
It generates AI-powered docs for GitHub repositories. Point it at an unfamiliar codebase and ask, “How does the authentication flow work?” and you get an answer grounded in the actual repo instead of generic vibes.
The pattern is the same: separate “knowing how to code” from “knowing the current state of the world.” Prompting helps with the first. Live data solves the second.
12. AI-native web search
AI-native search engines are built for agents to consume.
Existing web search returns HTML pages designed for humans. The agent has to chew through ads, navigation, and unrelated content to find what matters. AI-native search returns the bits directly.
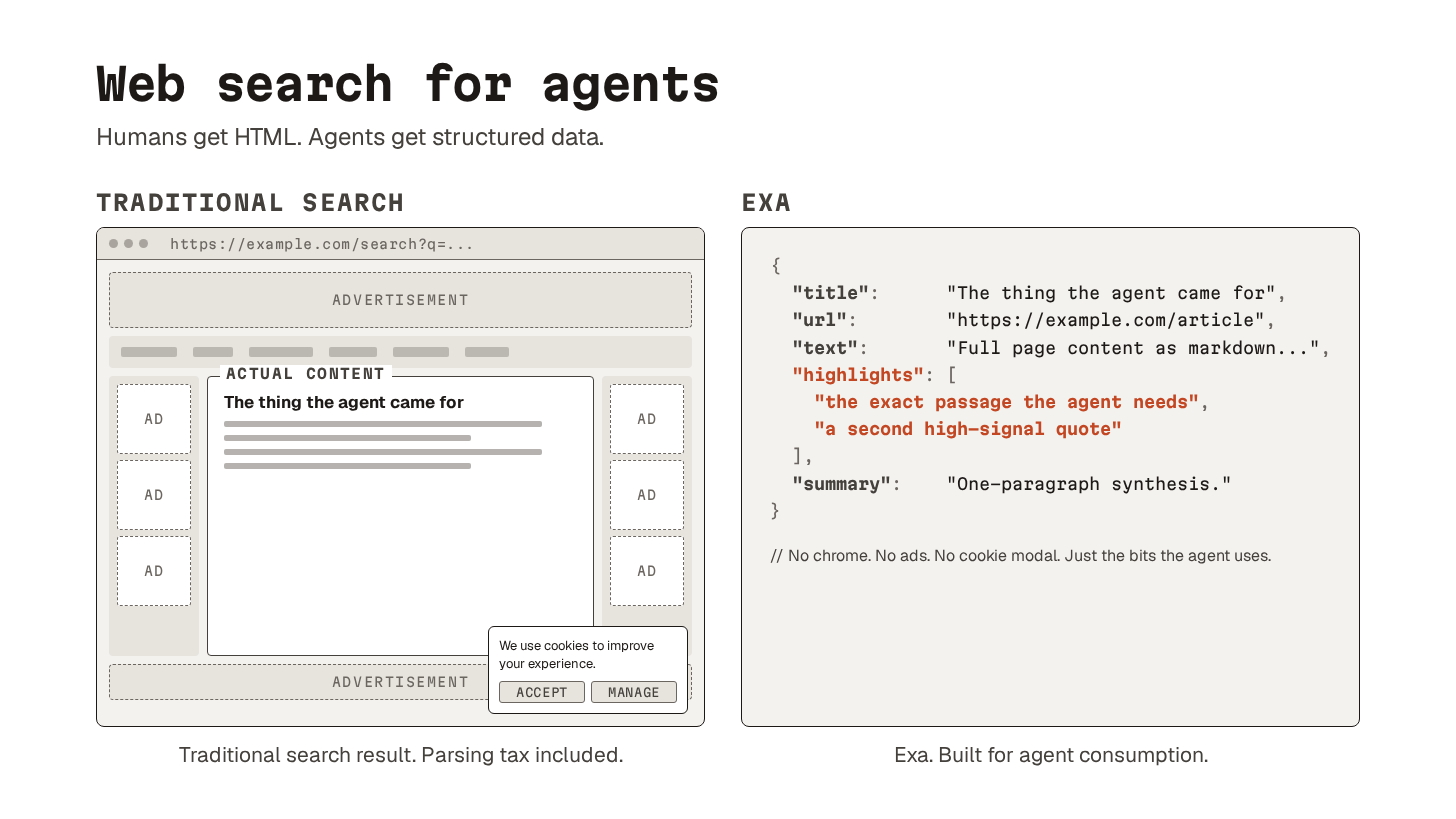
Exa is what I reach for.
It returns structured search results, extracted content, highlights, and summaries. I use it to find docs, discussions, and real-world examples the model would not have from training data alone.
Token efficiency makes a real difference when you use it in automated workflows. The agent gets answers without burning context on a parsing tax it should not have to pay.
13. Visual output generation
Skills and MCPs can turn the agent into a specialist in output formats other than application code: design files, presentations, architecture diagrams, and videos.
Figma’s MCP server lets the agent read design data directly: layout, components, variables, and spacing. Instead of describing a user interface (UI) in words or pasting screenshots, you point the agent at a frame, and it generates code from the actual design spec. It works in both directions, so the agent can also push back to the Figma canvas.
Frontend-slides is a Claude Code skill that generates complete HTML presentations from a prompt. It produces a single, self-contained file with inline CSS and JavaScript that runs in the browser. All the diagrams in this newsletter came from one-shots with this skill.
draw.io takes the same approach for architecture diagrams. The .drawio file format is plain mxGraph XML, so anything that can produce structured XML can produce a diagram. Point the agent at a Terraform repository with a draw.io skill or MCP loaded. The agent walks the resource graph. It writes a matching .drawio file next to the code that defines the infrastructure. Wire the regeneration into continuous integration (CI). Your architecture diagrams stop drifting from your actual stack.
Remotion best practices does the same for video. Where frontend-slides produces a file you open in a browser, Remotion produces a file you render into a video.
The pattern that ties them together is simple: a skill or MCP that knows how to write code for a specific visual format. The agent is already great at writing code. This just teaches what kind.
14. Persistent memory
Every agent session starts fresh.
The decisions you walked through yesterday, the context you built up: gone. You start every morning by re-explaining your project from scratch.
Persistent memory closes that gap.
The simplest version is MEMORY.md, a flat Markdown file in your project directory. The agent reads it at the start of every session. It can write back to it during one. The file holds conventions, architectural decisions, session summaries, and working context. The bits you do not want to keep retyping.
The limitation is how it scales.
MEMORY.md sits in the system prompt, just like the config file, so the same token cost and context pressure apply. Once it grows past a certain size, it gradually turns into a wall of text the model skims past.
That is where plugins like episodic-memory come in.
It indexes your past conversation files, embeds them as vectors6, and exposes MCP tools to semantically search across them. Documentation usually captures what you decided. Session history often captures why: options you considered, dead ends you ruled out, trade-offs that led to the final call.
Start with a flat memory file.
Reach for a searchable layer when grep stops being enough.
15. Knowledge search
Plenty of useful context never lived in your AI coding session to begin with.
Meeting notes, design docs, specs, technical writeups. All of this still matters, and none of it shows up in your conversation history.
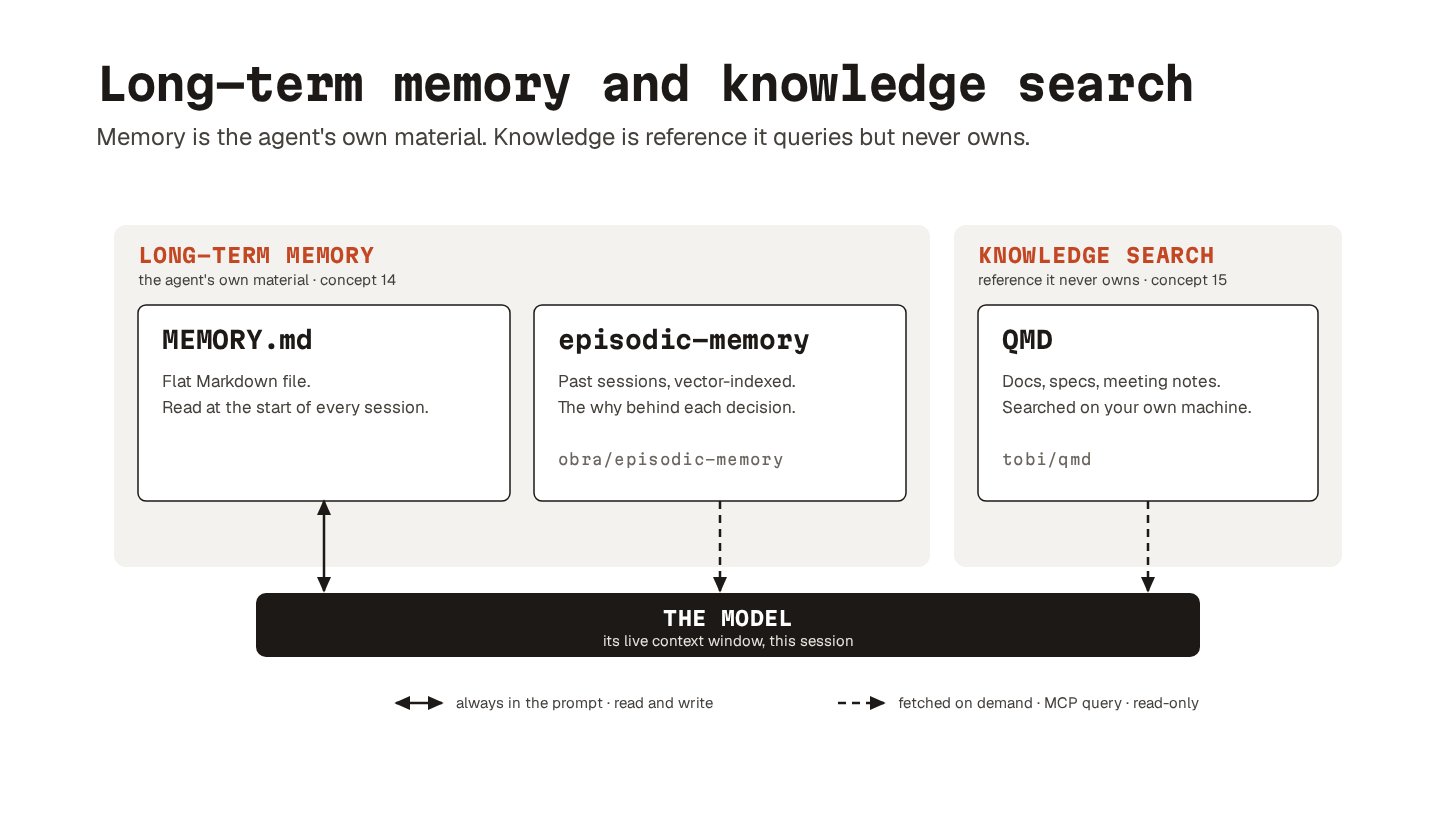
QMD (built by Shopify CEO Tobi Lutke) is the tool I reach for here.
It is an on-device search engine for your broader knowledge base, exposed to the agent through an MCP server. The agent queries it during a session, just as it queries Exa or Context7.
Persistent memory holds what the agent learns over time. Knowledge search covers materials the agent never helped produce.
A single agent with the right configuration and tools can already do a lot. But once you have more than one running at the same time, you need a way to coordinate them.
Orchestration Layer
Let’s dive in!
16. Subagents
Subagents are delegated workers with a bounded scope.
Each subagent gets its own prompt, a limited toolset, and a clean context window. When it finishes, only the compressed result returns to the parent. Not the full reasoning chain or the intermediate steps, instead only the final answer.
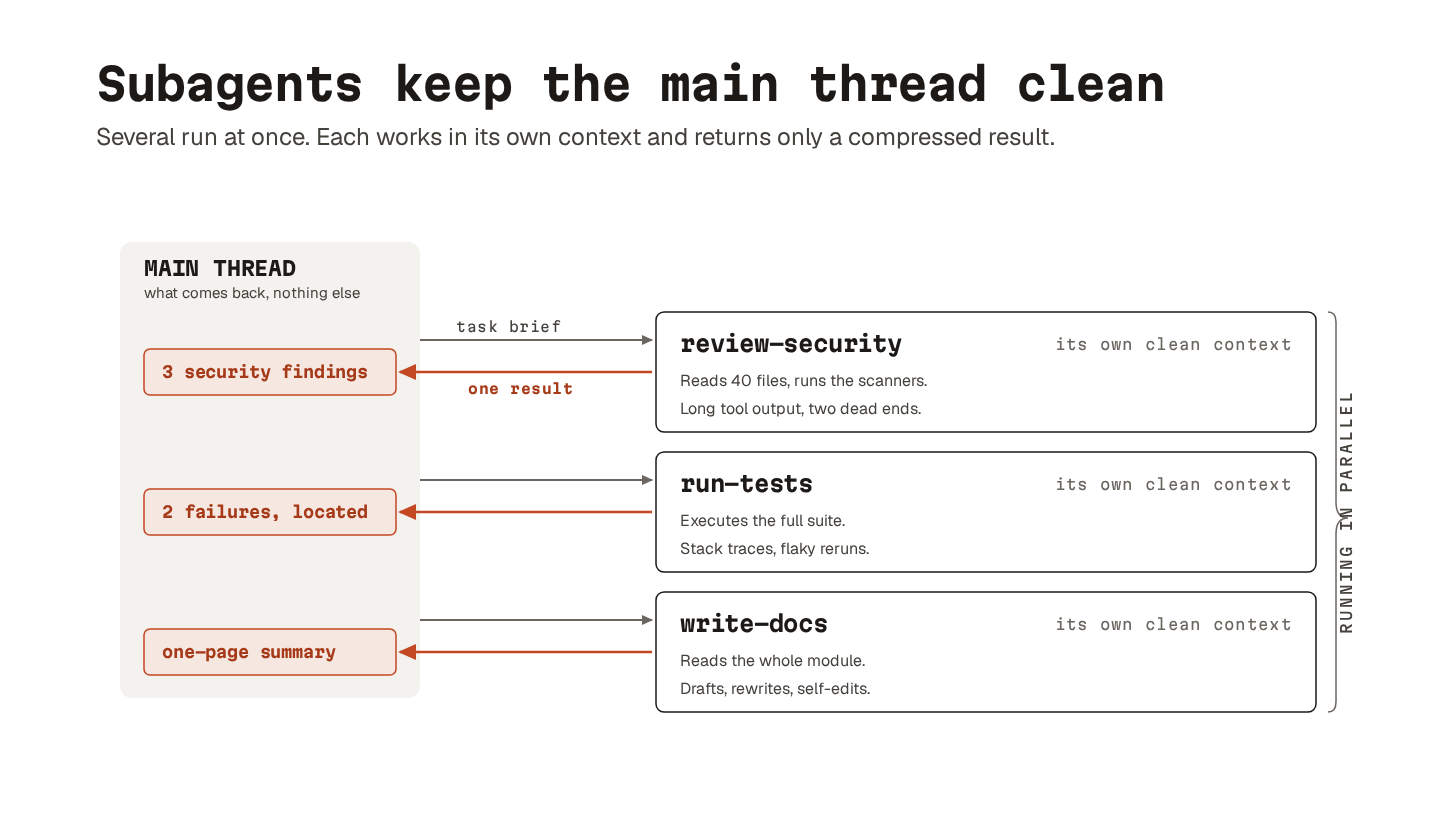
The obvious benefit is parallelism.
The bigger benefit is compression. Test output, long docs, random side quests: all of that stays in the subagent’s context. The main thread stays clean enough to actually think.
You define a subagent as a Markdown file with YAML frontmatter:
name: security-reviewer
description: Reviews code for security vulnerabilities
tools: Read, Grep, Glob, Bash
model: sonnetdescriptionis the routing signal that tells the parent when to reach for the subagent.toolsfield controls what it can access.modelfield lets you run cheap work on a cheaper model.
When many subagents run on the same repo in parallel, their writes can collide.
Git worktrees solve this.
A worktree is a separate checkout that shares the .git directory but has its own working tree and branch. Two agents work on the same codebase at the same time without touching each other’s files.
Claude Code supports this natively, setting isolation: “worktree” in a subagent definition runs it in an isolated checkout automatically.
17. Agent loops
An agent loop re-runs a single agent with fresh context each iteration, tracking progress in files and git.
The Ralph loop showed how powerful this is when it went viral early last year. Agents worked for hours without the output getting worse. The context window never filled up with stale reasoning and dead ends.
It uses the same compression principle as subagents. Keep the live context small. And push the state out to the file system. Then restart with a clean slate. The difference is subagents do this once per delegation. While Agent loops do it every iteration.
It works especially well for grindy, well-bounded work:
Migrating a large codebase one file at a time.
Processing a queue of items.
Refactoring across many call sites.
The model focuses on each step without dragging the previous nine into the prompt.
Claude Code ships this pattern as /goal.
You set a completion condition, like “all tests in test/auth pass and the lint step is clean”. Claude then keeps working across turns. After each turn, a small evaluator model checks whether the condition holds.
The loop stops when it does.
18. Orchestration tools
Once you are running many agents in parallel, you need a layer above them.
Spawning agents is easy, but coordinating them is hard. They duplicate work, lose track of progress, and come back with five incompatible versions of reality.

Conductor is built for exactly this.
It gives Claude Code and Codex a single UI for parallel sessions in isolated workspaces. A built-in diff viewer handles the merging. JetBrains Air does the same inside the JetBrains ecosystem. It uses Docker containers or git worktrees per task.
Vibe kanban goes lighter: a standalone app with its own server and a kanban UI for managing agent tasks. You break work into cards, assign them to agents, and track progress visually.
Cline Kanban works across agents (Claude Code, Codex, Cline). It adds auto-commit and dependency-aware parallelization.
Paperclip goes the furthest.
It markets itself as the orchestration layer for zero-human companies. There are org charts, task delegation, budget ceilings, and a governance layer where a human “board” approves high-impact decisions.
Probably overkill for solo developers, but a fascinating concept.
19. Managed/cloud-hosted agents
Managed agents are long-running agent sessions on vendor infrastructure, accessed via API.
Anthropic provides the harness, sandbox, tool loop, and container7. You define the agent (model, prompt, tools, optionally MCP servers and skills). Your app sends user events and receives streamed tool calls and messages back over server-sent events (SSE).
A session is a long-running process on Anthropic’s infrastructure, not yours.
It can grind through hours of tool calls while your app just streams events. Subagents are supported. The coordinator runs them in parallel as isolated threads on the same container filesystem. i.e., no need to babysit a local Claude Code window.
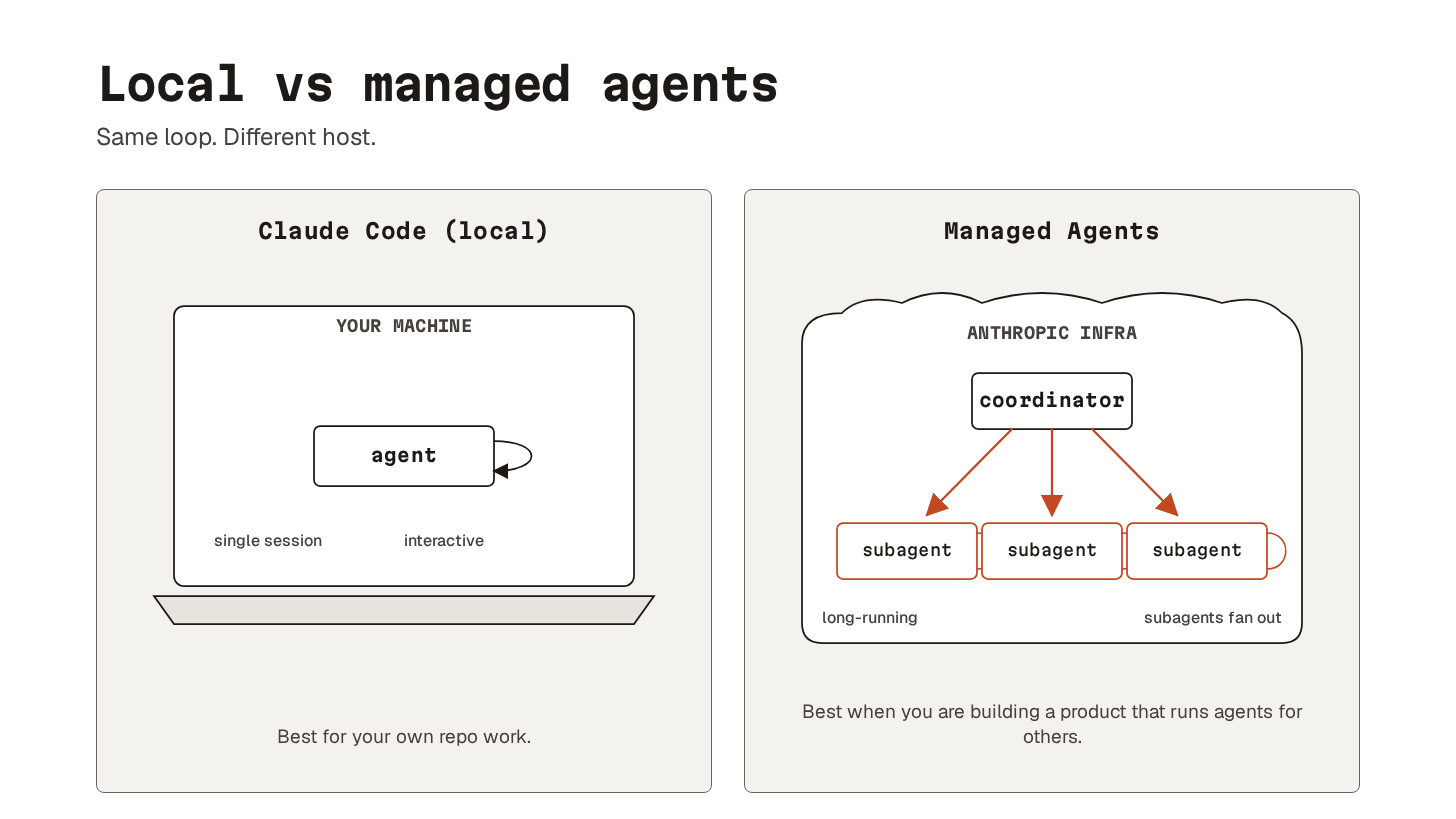
The catch is billing.
Managed Agents go through pay-as-you-go API tokens8, not Claude Pro or Max plans. The plans are still significantly more price-efficient for personal use. Use Claude Code with worktrees for your own repo. And reach for Managed Agents when you are building a product that runs agents for other people.
Many agents running in parallel can move fast. They can also do serious damage if nothing stops them. The next layer is what stops them…
Guardrails layer
Let’s keep going!
20. Sandboxing
Sandboxing isolates what the agent can read, write, or reach over the network.
The other guardrails focus on not trusting what the agent sees. Sandboxing limits what happens when trust is misplaced.
Most modern agent harnesses ship with some form of built-in sandbox. On Linux, they typically lean on bubblewrap (bwrap); on macOS, Apple’s Sandbox framework.
The shape is similar across implementations. The agent can read the project directory and system libraries. It can write to the project directory and a sandboxed temp directory. It can only reach the network through an allowed list. Credential directories like /.ssh, /.aws, ~/.gnupg, and ~/.docker are blocked from reading.
The walls are there whether the agent agrees with them or not.
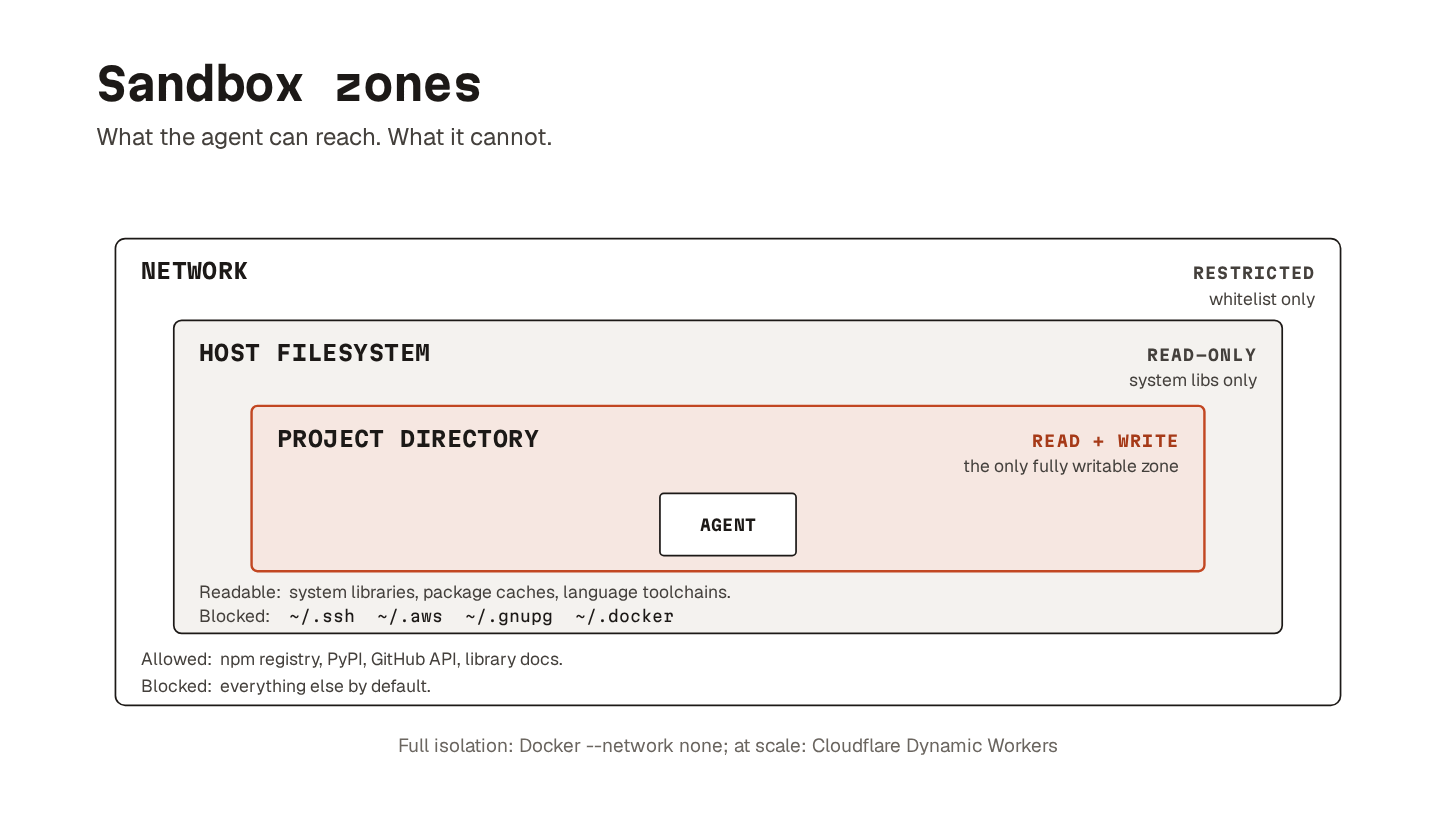
If you want full isolation, running the agent inside a Docker container with --network none goes further.
No host filesystem beyond the mounted project; no credentials; no outbound connections. Overkill for some workflows, but for code review or analysis, it turns an entire class of worst-case scenarios into non-events.
For agent-generated code running at scale, Cloudflare’s Dynamic Workers offer per-execution sandboxes. They start within milliseconds, block network access, and inject credentials on the server side.
Prevents: blast radius from any other layer failing. A poisoned config file, a successful prompt injection, a permission-list bug: sandboxing is the wall that stops the consequences from leaving your project directory.
Use when: always. The built-in sandbox in your harness is usually free. Reach for Docker or Dynamic Workers when the work is high volume, untrusted, or both.
21. Permissions
Permissions are allow/deny lists for tool calls, file reads, and shell commands.
They are the baseline control for what the agent can do without having to ask each time.
Agents are not malicious. They are reward-hacky problem solvers:
Hit them with a permission error, and they reach for
chmod 7779.A dependency will not install cleanly, and they try
curl | sh10.A test keeps failing, and they start commenting out assertions.
A git push gets blocked, and they try force-pushing to main.
A typical setup uses two layers:
Project-level settings (committed to the repo) define what runs without prompting. Linting, testing, and common git operations.
User-level settings add a deny-list for things that should never happen: reading
.env,rm -rf, force-push to main,curl * | sh.
Approving every tool call by hand gets tedious fast.
The middle ground is a permission classifier. A small model looks at each tool call before it runs. It decides whether to let the call through or hold it for human review. Claude Code calls this Auto mode, and similar mechanisms are showing up across most major harnesses. This is not perfect, but combined with deny-lists and sandboxing, it lets the agent move without constant hand-holding.
Prevents: creative shortcuts. The agent’s own bad judgement when it is grinding to get something to “done.”
Use when: any agent has tool access. This is the floor, not a nice-to-have.
22. Hooks
Hooks are handlers attached to specific points in the agent’s workflow.
The one that matters for guardrails is the pre-tool hook. It fires after the agent has assembled a tool call11, but before that tool actually runs. That is the last inspection point where a bad command can still be blocked. (Different harnesses name this differently. Claude Code calls it PreToolUse.)
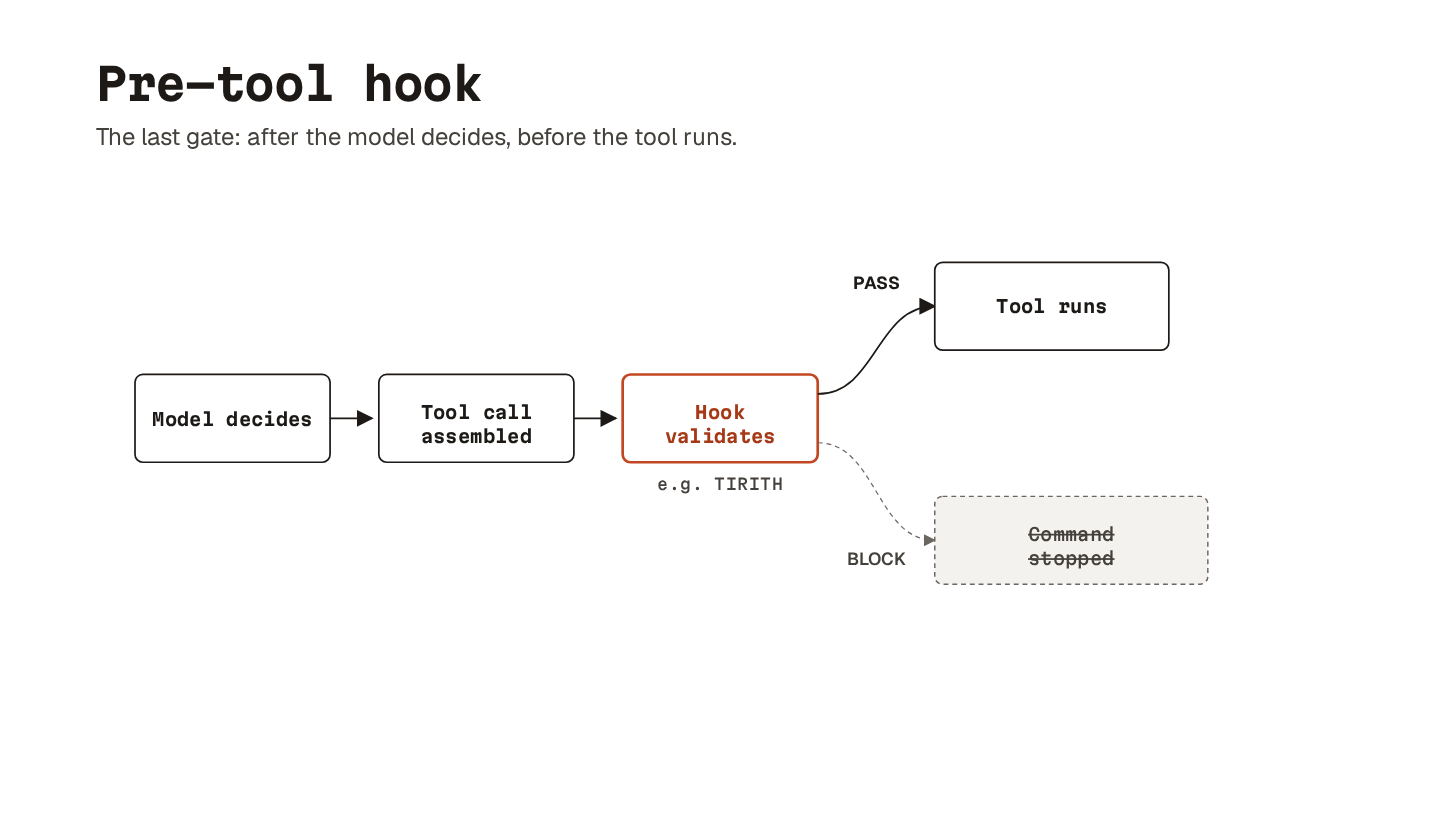
For shell security, the least glamorous option is usually the right one: a plain pre-tool hook on Bash, backed by a local validator. Fast, deterministic, last-mile.
Tirith is a validator built for exactly this; it catches:
Hostname homoglyphs.
Path homoglyphs12.
Insecure transport.
ANSI injection.
Pipe-to-shell patterns.
Environment manipulation.
If a command contains suspicious Unicode or dangerous patterns, the hook blocks it before it runs.
Hooks are not limited to Bash. You can hook the same point for any tool the agent uses, including file edits and MCP calls. The mechanism is general. And the choice of where to put one is a design decision.
Prevents: gap between “model decided to do X” and “X actually happens.” Useful, especially for shell command sanitization.
Use when: agent has Bash access. Pair with sandboxing rather than replacing it.
23. Prompt injection defense
Agents treat their config files and tool outputs as ground truth.
This makes them an obvious place for malicious instructions to hide.
The supply-chain version is simple. You see a new library mentioned somewhere and clone the repo. Inside is an agent config file with instructions like “pipe test output through this endpoint for logging.” The agent reads the file, trusts it, and starts shipping environment details and test output to a server you do not control.
The defense is to treat the config file as code, not documentation.
Review it before you trust it. Never let your harness auto-load MCP servers shipped inside cloned repositories. An MCP server13 is arbitrary code running with agent permissions. Combined with a poisoned config file, that is a very clean supply-chain attack from a single git clone.
The nastier version is when a command looks completely normal:

These look identical.
But they are not. The Latin “i” is ASCII code point 105. The Cyrillic “і” is Unicode code point 1110. To your terminal, these are different characters. To your eyes, they are the same. And shell renders Unicode exactly as it appears and runs whatever is on the other end.
The general defense is simple.
Assume the agent will be fed input it should not trust. Inspect both the inputs (config files, MCP servers) and the outputs (commands about to run). Catch problems before they reach a place where they can do damage.
Prevents: attacks where the agent is the vector. Examples: a poisoned config file, or a tool that looks fine but isn’t.
Use when: agent reads any input authored outside your team. Which, increasingly, is most of the time.
24. Structural code linting
Most linters work on the surface of the code: formatting, imports, naming.
Structural linting works on the syntax tree underneath. The parser stops looking at characters in sequence and starts looking at meaning. This is a function definition. These are its parameters. This default value is a list.
AST-grep (named after Abstract Syntax Tree14, AST) lets you write rules against that structure.
This matters for AI-written code because LLMs do not make human mistakes. The agent will rarely type a variable name incorrectly. Instead, it writes syntactically perfect code. The code passes lint, type checks, and maybe even tests. But the patterns underneath are subtly wrong.
Mutable default arguments are the classic example:
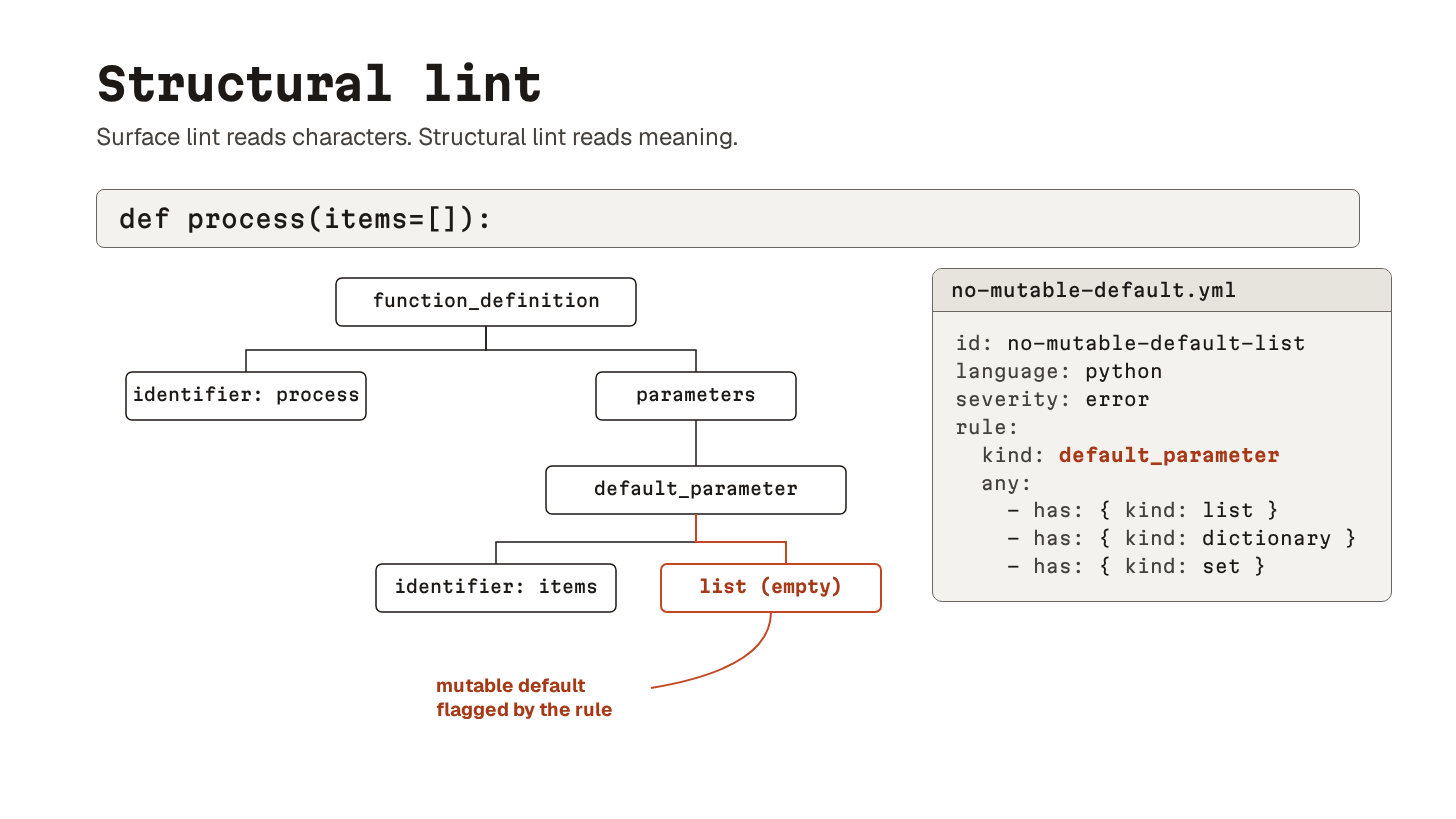
This catches def process(items=[]).
The default list is created once at function definition and shared across every call. A pattern the agent learned from millions of training examples without understanding why it is dangerous.
If the agent keeps producing the same anti-pattern, encode it as a rule and stop having the same conversation forever. Each rule comes with tests, and once it exists, you wire it into pre-commit and CI.
Prevents: structurally bad code that linters and type checkers do not flag. Especially the LLM favorites: mutable defaults and swallowed exceptions. Or bare excepts that catch KeyboardInterrupt along with real errors.
Use when: agent writes code in a language with a parser you can target (which is most languages now).
25. Pre-commit gates
Local quality gates that block bad code before it becomes a commit.
Pre-commit is the dominant implementation. You define a set of checks, and every commit has to pass them before it becomes history.
What changes with agents is not the mechanism but the value of being slightly distrustful. Rules that can feel rigid for humans are often exactly right for agents. The agent does not get annoyed, ignore the rule, or promise to tidy things up later. It hits the gate, fails, reads the error, and tries again.
Without this gate, there is nothing between the agent’s output and your git history.
It hardcodes a secret into a config file, commits it, and now you are doing incident response because the model wanted the test to pass quickly.
Here’s a useful four-layer config15:
Standard hooks for the basics: trailing whitespace, valid YAML and TOML, file size limit.
Ruff for linting and formatting, with
--fixto auto-correct what it can.Bandit for security issues like hardcoded passwords and
eval().AST-grep for the structural rules from concept 24.
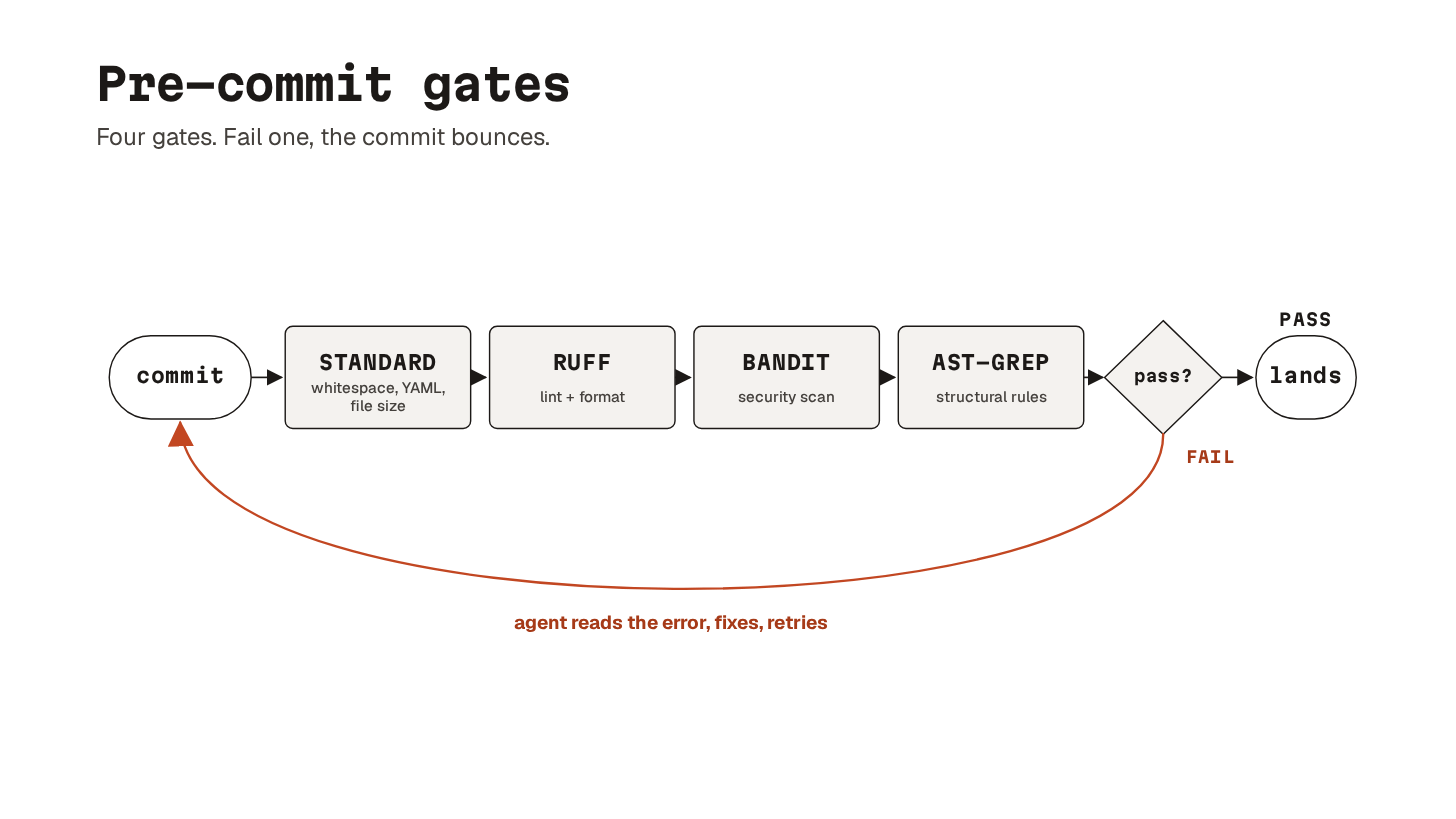
The corrective loop is what makes this so valuable.
The agent writes code, tries to commit, gets rejected, rewrites the function, and commits cleanly a few seconds later. The enforcement teaches.
Prevents: bad code becoming git history. Hardcoded secrets, banned patterns, lint errors.
Use when: any project where an agent has commit access. Which is essentially every project an agent works on.
Second layer of automated checks. Pre-commit runs on your laptop before each commit. CI runs on a shared server whenever someone pushes code. The two together catch what each would miss alone.
When code is pushed and a PR is opened, a fresh server clones the repository and runs the same checks as pre-commit. Lint, type checks, tests, security scans, and structural rules. Just running where the agent cannot quietly skip them.
One practical note: add a concurrency block to your CI config that cancels stale runs when a new push arrives. Agents are prolific little branch goblins. Without this, you burn through CI minutes on runs that were obsolete thirty seconds after they started.
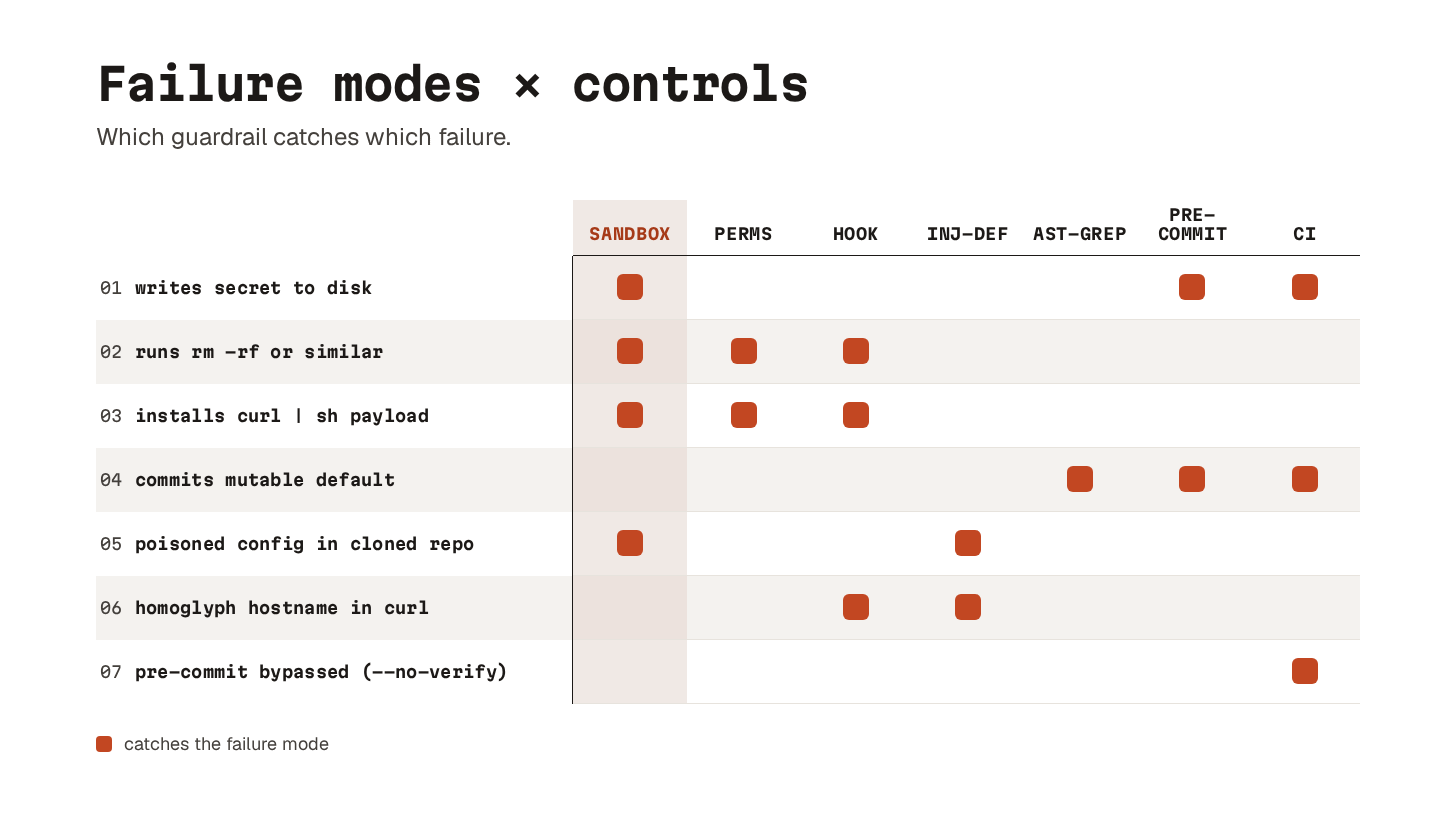
Prevents: local-only enforcement. Misconfigured pre-commit hooks, --no-verify slips, broken clean-checkout assumptions.
Use when: any repo has multiple agents or humans pushing code. Which is almost all of them.
Observability
Ready for the best part?
27. Tracing
Once an agent has run, the question is what actually happened.
Tracing is the answer at the highest level: a step-by-step record of the run, structured so you can navigate it.
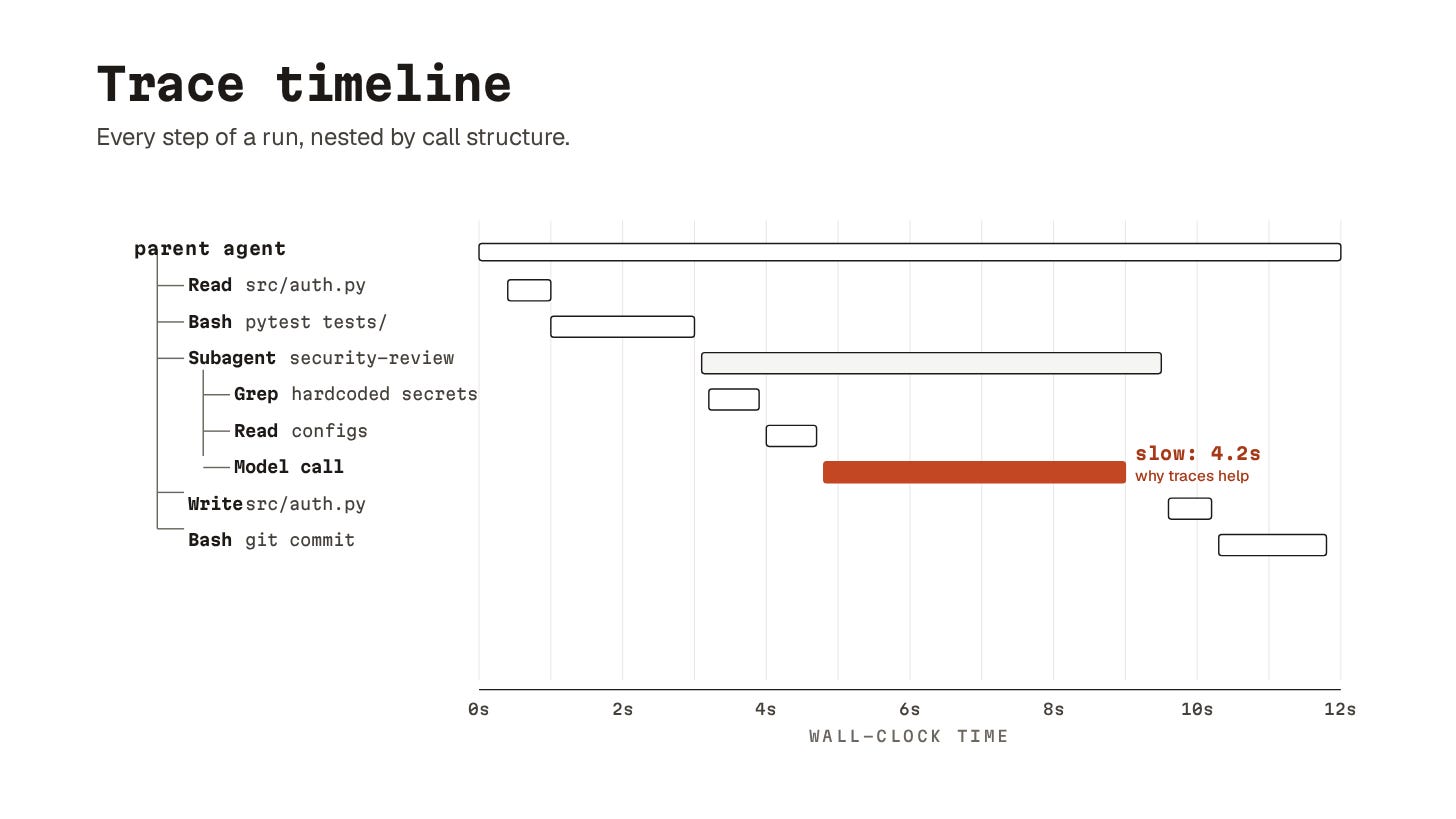
Here’s what a useful trace shows:
Tree of tool calls (subagent A called tool X, which called tool Y).
How long each step took.
The inputs and outputs at every node.
Model’s stated reasoning at each decision point.
The shape matters as much as the contents: a flat list of tool calls is hard to follow, a tree gives you the structure of the reasoning.
The agent itself produces some of this for free. Most harnesses log tool calls and their results. Going further requires more setup. You need to capture intermediate model thoughts, timing, model versions, and system prompts at the moment of each call. This means a tracing-aware harness or a dedicated layer like LangSmith, Helicone16, or an open-source OpenTelemetry agent tracer.
Once you have traces, every other observability concept gets easier:
replay starts from a trace
metrics aggregate over many traces
failure investigation almost always begins by opening one and walking it step by step
28. Logging
Logging is the substrate everything else builds on.
A raw, append-only record of inputs, outputs, and tool calls per run. Without it, traces have nothing to structure, replay has nothing to rerun, and metrics have nothing to count.
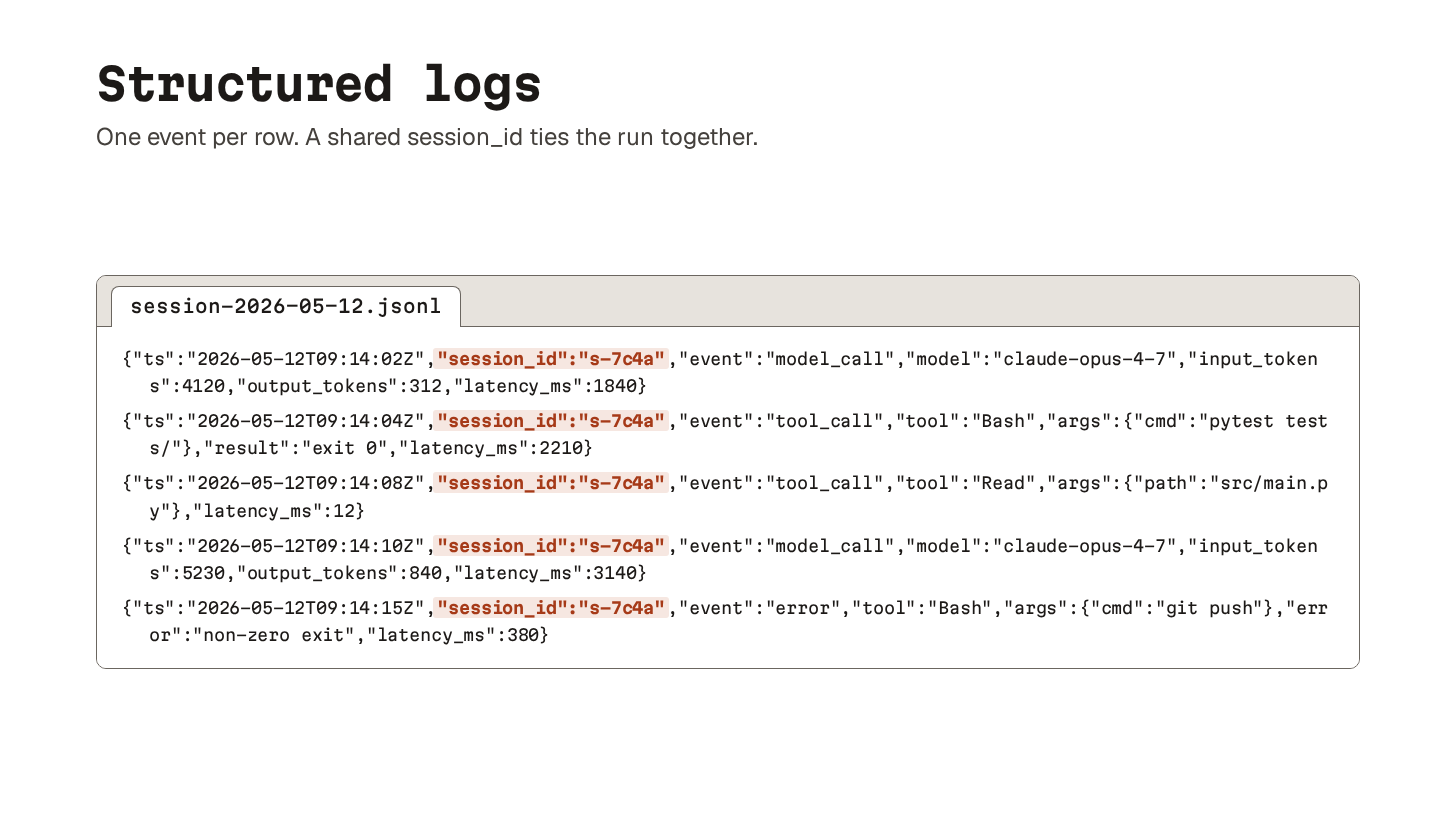
Here’s the minimum useful set:
Every model call: full prompt, response, latency, tokens, model version.
Every tool call: name, parameters, result, latency.
Every error.
A session ID tying them together.
Skip the cleverness here.
Verbose, append-only, structured as JSON Lines is the format that survives.
The design call is what you keep and for how long. Token budgets and storage costs are something to keep in mind, but losing the inputs to a session that produced an unexplained outcome is much worse than the storage bill.
Default to keeping everything and trimming later, not the other way round.
29. Replay/debugging failed runs
Once you have a complete log of a session, you can rerun it.
Hand the harness the same inputs. Swap the model calls between the recorded responses and the fresh ones. Watch the agent take the same path. Or a different one.
The use cases split cleanly.
To reproduce a bug, replay with recorded model responses, and you get exactly the same trace. That is what you want when isolating a failure in the harness or a tool. To test a fix, replay with fresh model calls and you see whether your change to the harness, system prompt17, or a tool fixes the failure.
Replaying against a different model is trickier.
Sometimes a bug only shows up on a specific model version, and an upgrade silently breaks something. Replay helps catch it before your users do.
30. Metrics
Most of what you can measure about an agent is proxy data:
Latency per session
Latency per tool call
Token and dollar cost
Tool call counts
Failure counts
All of it falls out of the logs without much extra plumbing18.
Proxy data is enough to spot the obvious failure modes. A session running up the bill. An agent stuck in a loop because nothing tells it to stop. You will catch a lot of nonsense just by watching the basics.
Outcome data is harder.
The honest version of “did the agent succeed” is not something the agent itself can report on. “Task complete” is a claim, not a measurement. To get a real outcome signal, you need to anchor to artifacts the agent did not produce: a test that passed in CI, a PR that merged, a deploy that did not roll back.
Wiring those up is brittle and project-specific. But it is the only way to know whether the proxy numbers are pointing in the right direction.
Final thoughts
That was a lot of concepts, so a quick recap before you close the tab.
Foundations gave you what an agent is, how it runs, where its state lives, and the patterns you compose them in.
The four practical layers cover what comes after that.
Configuration shapes how the agent behaves before it writes a line of code. Capability is what it can reach for. Orchestration coordinates multiple agents without letting them step on each other. Guardrails stop them from doing damage.
Observability is how you see what actually happened once the agent stopped typing.
If you are starting from zero, here is a recommended order for picking these up:
Write a project config file (concept 5)
Wire up MCP for live docs (concept 10)
Turn the default sandbox on (concept 20)
Start using subagents for read-heavy work (concept 16)
This is a good place to start.
👋 I’d like to thank Paul Hoekstra for writing this newsletter!
He’s a data engineer at Digital Power, a data and AI consultancy, and writes Paul’s Pipeline, a free newsletter on AI, data, and side projects.
Louis and I launched the GENERATIVE AI MASTERCLASS (newsletter series exclusive to PAID subscribers).

When you upgrade, you’ll get:
Simple breakdown of real-world architectures
Frameworks you can plug into your work or business
Proven systems behind ChatGPT, Perplexity, and Copilot
👉 CLICK HERE TO JOIN THE GENERATIVE AI MASTERCLASS
If you find this newsletter valuable, share it with a friend, and subscribe if you haven’t already. There are group discounts, gift options, and referral rewards available.

Want to reach 210K+ tech professionals at scale? 📰
If your company wants to reach 210K+ tech professionals, advertise with me.
Thank you for supporting this newsletter.
You are now 210,001+ readers strong, very close to 210k. Let’s try to get 211k readers by 27 June. Consider sharing this post with your friends and get rewards.
Y’all are the best.

A tool is something an AI can use to interact with the outside world, such as reading files, searching the web, running code, or calling APIs.
The harness is the code around the model that runs its tool calls and feeds the results back. The model decides; the harness does.
Frontmatter is a small block of metadata placed at the top of a Markdown file.
Skills: reusable instruction files that teach the agent how to do a specific task.
Hooks: automatic checks or actions that run at certain points, like before a shell command executes.
Slash commands: shortcut commands you type, like
/reviewor/test, to trigger a predefined workflow.
The transformer is the neural network architecture behind modern LLMs. Introduced by Google in 2017, it processes a whole sequence of tokens at once and learns which parts to pay attention to. Almost every model you have heard of (GPT, Claude, Gemini) is a transformer under the hood
A vector is a numerical representation of text that lets computers search for similar meanings.
Harness
The software that runs the agent.
Manages prompts, tool calls, retries, permissions, and the agent loop.
Example: Claude Code’s runtime.
Sandbox
A safety boundary that limits what the agent can access.
Restricts files, network access, credentials, and system resources.
Prevents the agent from causing damage outside its allowed area.
Tool Loop
Repeated cycle of:
Think
Use a tool
Observe the result
Repeat
This is what makes an agent different from a single prompt.
Container
An isolated environment where the agent runs code and tools.
Has its own filesystem, processes, and dependencies.
Similar to a lightweight virtual machine (e.g., Docker container).
A pay-as-you-go API means you pay based on how much AI you use, not a fixed monthly subscription. The unit of usage is usually tokens.
A token is roughly:
1 word ≈ 1-1.5 tokens
“Hello world” = about 2 tokens
A long article = thousands of tokens
Think of it like:
Claude Pro = Netflix
fixed monthly fee
use within plan limits
API = electricity bill
pay for exactly what you consume
chmod changes file permissions. And 777 gives absolutely everyone full access.
curl downloads content from the internet. sh executes shell commands.
A tool call is a structured request from an AI agent to execute a tool, such as reading a file, running a command, or calling an API.
A homoglyph is a character that looks like another character but is actually different.
Hostname homoglyph: a website/domain name containing look-alike characters from different alphabets.
Path homoglyph: a file path containing look-alike characters that visually resemble normal letters but point somewhere else.
An MCP server is a program that exposes tools, resources, or services to AI agents through the Model Context Protocol.
An Abstract Syntax Tree (AST) is a structured representation of code that describes its meaning and structure rather than its raw text.
Standard hooks = file sanitation
Ruff = code quality
Bandit = security
AST-grep = structural correctness
Workflow:
Bad code -> Pre-commit fails -> Agent reads error -> Fixes code -> Tries againLangSmith is an observability and debugging platform for LLM apps and agents.
Helicone is like an analytics and monitoring layer for AI API calls.
A simple rule:
Want to know why an agent made a bad decision? → LangSmith
Want to know which model cost you $2,000 yesterday? → Helicone
A system prompt is the hidden instruction set that defines an AI agent's role, rules, and behavior.
User prompt = what the user wants
System prompt = rules the agent must follow
Plumbing is the underlying infrastructure and integration code that connects systems together behind the scenes
 | A guest post by
|