
RAG - A Deep Dive
#132: Understanding Retrieval-Augmented Generation


Share this post & I'll send you some rewards for the referrals.
Every large language model1 (LLM) you use has lied to you with confidence, fluency, and frequency…
Ask any model about something that happened last week. It doesn’t know. It can’t know. Its knowledge was frozen months ago. They might try, and if they do, they will hallucinate.
This isn’t a bug.
It’s a fundamental architectural limitation. LLMs keep knowledge in their parameters2. These are billions of numerical weights learned during training. Once training ends, the knowledge is locked. The model doesn’t know what it doesn’t know, so it fills the gaps with confident fabrication. Studies show that hallucination3 rates can be as low as 1% for simple summarization tasks. However, they can exceed 58% for complex work.
This is exactly what Retrieval-Augmented Generation4 (RAG) solves.
RAG doesn’t bake knowledge into the model. Instead, it pulls in relevant context when you ask a question. The model stays smart, your data stays current, and every answer is traceable back to its source.
This is the architectural pattern that makes AI actually useful.
Here’s how it works, why it works, and how to build it:
Still juggling 10 different tools? Learn AI workflows and replace 80% of them (Partner)
Perplexity’s new computer thinks, designs, codes, and manages projects — all without you lifting a finger to switch tools.
This is where AI is headed: one place to get everything done. Smarter, faster, and built to make you 10x more productive.

Now is your chance to enter into your most productive era!
That’s why we recommend joining Outskill- the world’s first AI learning platform where over 10+ Million Learners have learnt from top industry leaders like Microsoft, NVIDIA, and Google.
They are hosting a 2-day LIVE AI Mastermind where you’ll build automations, create personalized agents, and learn to turn AI into your ultimate competitive edge.
You will also unlock exclusive bonuses for free when you show up: A Prompt Bible, AI monetization roadmap, and a personalized toolkit builder - for which you would have to pay $1000+ outside.
🧠 Happening LIVE- Saturday and Sunday
🕜 10 AM EST to 7PM EST
Register here before they run out of seats. (free for the next 72 hours only!)
I want to introduce Eric Roby as a guest author.

He’s a senior backend and AI engineer focused on building real-world systems and teaching developers how to do the same. He runs the YouTube channel @codingwithroby, where he focuses on backend engineering, and created the platform The Backend OS.
Through his content and courses, he helps engineers go beyond tutorials, think in systems, and develop the skills that actually matter for real backend roles.
Check out The Backend OS, built to close the knowledge gaps you don’t even know you have.
The Knowledge Problem
We need to understand why LLMs struggle with real-world knowledge before we fix them. The problem has three layers, and none of the obvious solutions work…
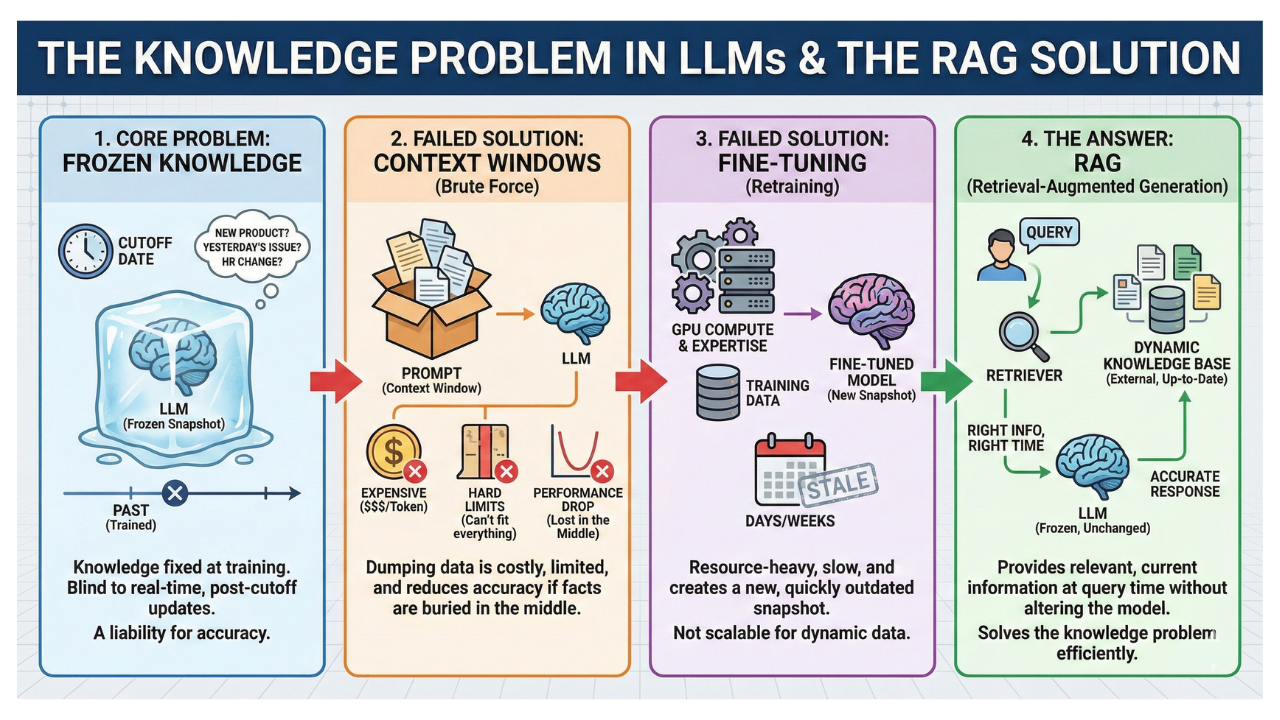
LLM knowledge is frozen at training time
Every LLM has a cutoff date for its knowledge.
Everything the model knows was scraped, processed, and compressed into parameters during training. After that date, the model is blind. It isn’t aware of your new product launch, yesterday’s security issue, or this morning’s HR policy change.
This isn’t a minor inconvenience.
In business, accuracy is crucial. This includes areas like customer support, legal analysis, internal search, and compliance. A model that can’t access current information is a liability. It doesn’t help the business at all.
Context Windows Aren’t the Answer
The brute-force approach is tempting: dump everything into the prompt.
Context windows5 have increased a lot. Some models can now handle over a million tokens6. But this approach has three fatal problems.
First, it’s expensive.
You pay for each token. Sending your entire knowledge base with every query will wipe out your budget.
Second, there are hard limits.
A million-token window can’t fit all of a large enterprise’s documents or its databases.
Third, and this is the one most people miss, models get worse with more context.
Research from Stanford and UC Berkeley shows LLM performance follows a U-shaped curve. Models do best when key information is at the start or end, but accuracy drops sharply when important facts are buried in the middle. In Liu et al.’s multi-document QA experiments, accuracy for some models dropped to roughly 25% when key information was placed in the middle of a 20-document context.
It’s clear: adding more context to the prompt doesn’t guarantee the model will use it.
Fine-tuning isn’t the answer either
Fine-tuning7 is when you take a pre-trained model and continue training it on your own specific data, so it learns new knowledge or behavior.
Fine-tuning changes the model’s weights to incorporate new knowledge. Think of it like sending someone back to school for a specialized course. In theory, this lets you teach the model about your domain.
In practice, it creates more problems than it solves…
It requires GPU compute, machine learning expertise, and carefully prepared training data. It takes days or weeks to complete. The result is a snapshot. Once your underlying data changes, your fine-tuned model becomes stale.
What’s Actually Needed
The key is to provide the AI with the right information at the right time for each query. And it should be done without changing the model itself.
That’s RAG.
Now let’s investigate RAG deeper:
What RAG actually is
Retrieval-Augmented Generation is an architectural pattern, not a product. The concept is straightforward, and the best analogy is an open-book exam.
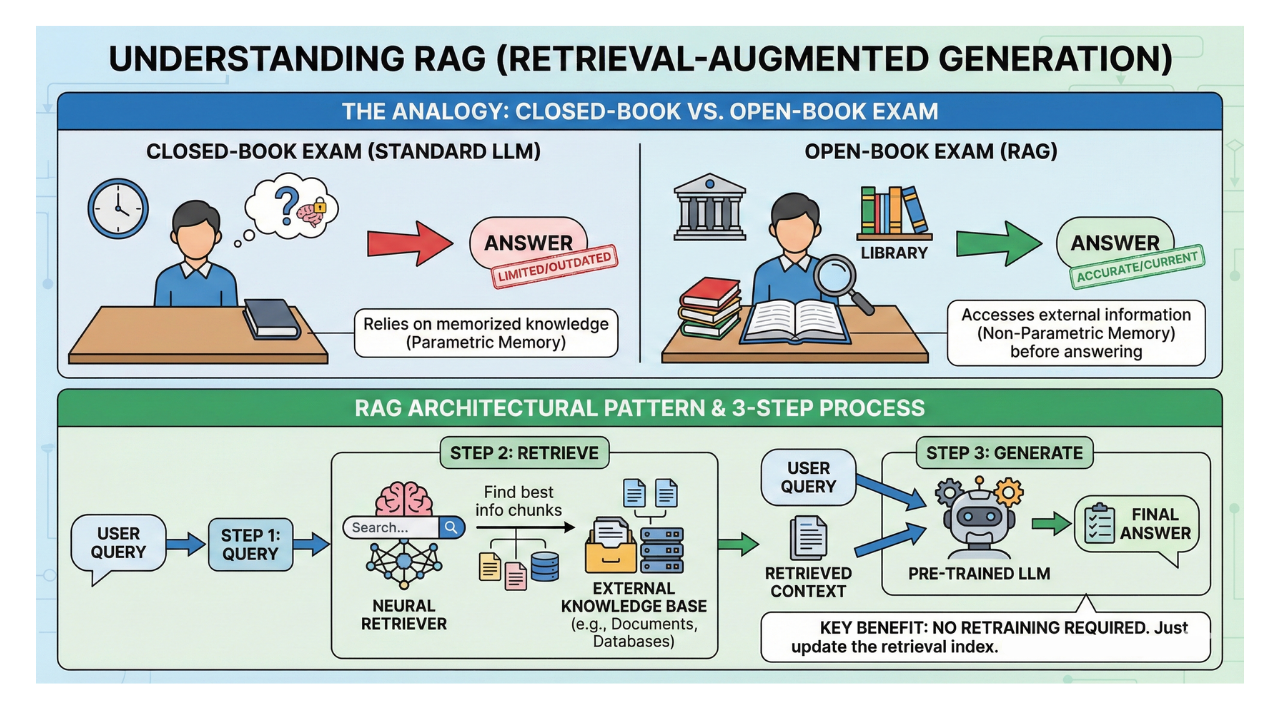
A student taking a closed-book exam relies on what they have memorized.
That’s a standard LLM. It’s smart and can reason, but it’s limited to what’s in its parameters. A student with an open-book exam has the same reasoning skills. They can check relevant pages before answering.
That’s RAG.
The formal definition comes from a 2020 paper by Patrick Lewis and his team at Facebook AI Research and University College London. RAG models combine parametric memory8 with a pre-trained language model and non-parametric memory9. This non-parametric memory uses an external knowledge index. It’s accessed by a neural retriever10.
You can still update the model’s knowledge by swapping the retrieval index. No one needs to retrain.
In practice, RAG follows a three-step loop:
Query comes in: a user asks a question.
Retrieve: System looks in an external knowledge base for the best information chunks.
Question and context go to the LLM. It then creates an answer based on the retrieved documents.
You’re not changing the model. You’re changing what it sees. That distinction makes RAG so powerful and so practical.
The open-book analogy makes sense at a high level. But understanding why it works so well means diving deeper into the topic…
How RAG Works Under the Hood
The three-step loop sounds simple. The engineering that makes it work is where things get interesting.
A RAG system has two main parts:
An offline ingestion pipeline that gets your data ready.
An online retrieval pipeline that answers queries.
Let’s walk through each one…
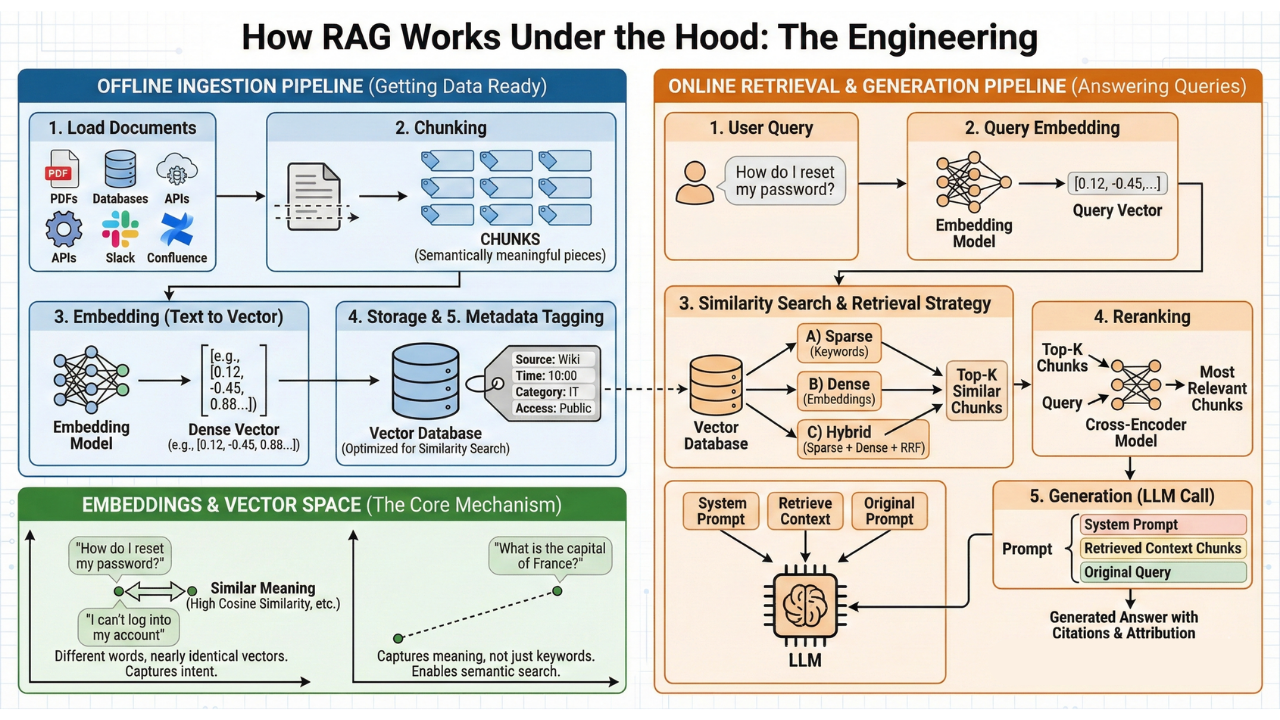
Embeddings: Core Mechanism
Before anything else, you need to understand embeddings11. This is the concept that enables semantic search12.
Text embeddings turn text into dense numerical vectors13. These are arrays of floating-point numbers, usually with 1,536 or 3,072 dimensions. They capture the text meaning. The magic is in what “capture meaning” means. Words and sentences with similar intent are close together in vector space. This happens even with different words.
Consider this: “How do I reset my password?” and “I can’t log into my account” use completely different words.
But when converted to embeddings, they produce nearly identical vectors. The distance between them is tiny because their meanings are similar. This is measured using cosine similarity14, dot product, or Euclidean distance.
The key insight for RAG is clear.
System finds relevant content. It does this even if the user’s question doesn’t use the exact words from the source document. It searches by meaning, not by keywords.
Data Ingestion Pipeline (Offline Phase)
First, process your knowledge base. Then, index it. Only then can your RAG system answer questions.
This happens in five steps:
What triggers the offline phase?
In traditional workflows, this pipeline runs when new data is available. This can happen when documents are added or updated. It can also occur when a database changes or on a regular schedule, like nightly or weekly. Some teams trigger re-ingestion if retrieval quality drops.
They also do this when a new data source connects:
Load documents from anywhere: PDFs, databases, APIs, wikis, Slack channels, and Confluence pages. Frameworks like LangChain15 and LlamaIndex16 offer ready-made connectors for many common sources.
Chunking17: Split documents into semantically meaningful pieces. This is the single highest-leverage step to get right, and we will cover it in depth later.
Embedding: Convert each chunk into a vector using an embedding model.
Storage: Store the vectors in a vector database18 optimized for similarity search.
Metadata tagging: Tag each chunk with source, timestamp, category, and access control information. This metadata becomes critical for filtering, attribution, and security later.
Retrieval Pipeline (Online Phase)
When a user asks a question, the retrieval pipeline kicks in:
Query embedding: User’s question turns into a vector. This uses the same embedding model from ingestion. This is critical: the query and the documents must live in the same vector space.
Similarity search: The system finds the top-K19 similar chunks. It compares the query vector to each vector in the database.
Retrieval strategy: This is where the real engineering decisions happen. Three primary approaches exist:
Sparse retrieval20 uses a statistical method that matches exact keywords. It weighs these matches using term frequency and inverse document frequency.
Dense retrieval (embeddings): Semantic search via vectors. Finds conceptually relevant content even when the wording differs.
Hybrid search (combining both): Use both sparse and dense retrieval. Then, merge the results with Reciprocal Rank Fusion21 (RRF). This boosts documents that rank high in both systems.
Re-ranking: After retrieving results, a cross-encoder model rescans them. It processes the query and each document as one input. This captures fine-grained relevance that bi-encoders miss.
Generation Phase
With the most relevant chunks in hand, the system assembles the final prompt:
Prompt Construction:
System Prompt: Combine the system prompt (the instructions that tell the LLM how to behave, like “You are a helpful customer support agent”) with the user’s request.
Retrieved Context Chunks: Integrate the relevant pieces of text pulled from your knowledge base. For instance, if someone asks, “What’s your refund policy?” You might pull two paragraphs from your company’s policy document.
User’s Original Query: Include the user’s actual question or task — exactly as they typed it.
LLM Call: The model generates an answer grounded in the retrieved documents. The key facts are in the prompt. The model uses these facts to reason instead of relying on its trained memory. Think of it like giving someone an open-book exam instead of asking them to answer from memory.
Citation and Attribution: The system shows which source documents were used and provides verifiable citations. For example, the response might say, “Based on Section 3.2 of the Employee Handbook...” so the user knows exactly where the answer came from. This is one of RAG’s biggest advantages over fine-tuning: transparency.
Now that you know how RAG works mechanically, the real question is whether it’s the right tool. That depends on what you’re comparing it to…
Why RAG over alternatives?
RAG isn’t the only approach to giving AI access to knowledge.
You need to know when to use it and when not to. This means comparing it to other options.
RAG vs. Fine-Tuning
This is the comparison most teams face first. Here’s how they stack up:
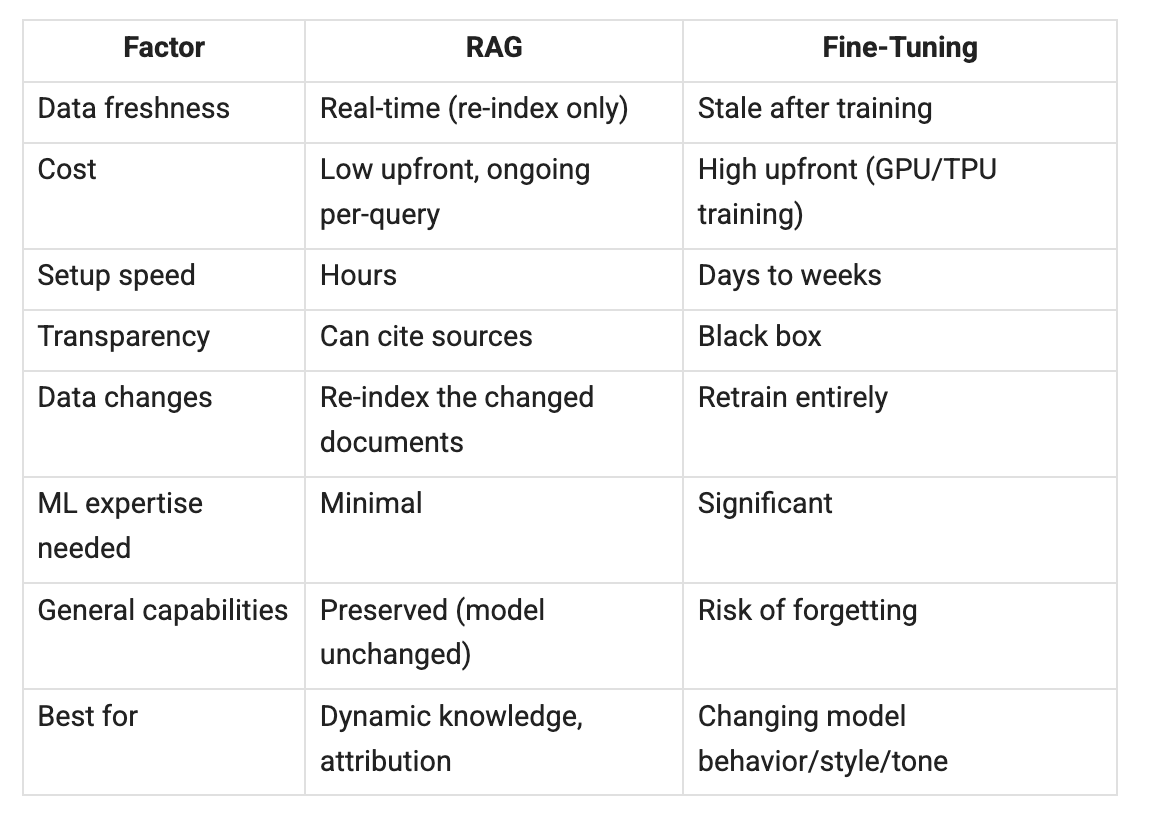
The key nuance: fine-tuning and RAG are complementary, not competing.
Fine-tuning is the best option when you want to adjust the model’s behavior, style, or output format, not just its knowledge. The best production systems do two things: they fine-tune style and behavior, and then they use RAG for knowledge. You can adjust a model to produce structured JSON in a certain format.
Then, use RAG to fill it with up-to-date data.
RAG vs. Long Context Windows
Context windows keep growing. Why not dump everything in the prompt?
Cost and precision. RAG retrieves only the 5-20 most relevant chunks. Long context stuffs everything in and hopes the model finds the needle. RAG is cheaper per query. It’s also more precise in what it finds. Plus, it can search millions of documents, unlike others that have a token limit.
They work well together: first, use RAG to get the right 20 chunks.
Then, use long context to process them all at once. The “lost in the middle” research shows that retrieving small, relevant chunks works better than using large context windows.
Reminder: this is a teaser of the subscriber-only newsletter series, exclusive to my golden members.
When you upgrade, you’ll get:
High-level architecture of real-world systems.
Deep dive into how popular real-world systems actually work.
How real-world systems handle scale, reliability, and performance.
Traditional RAG vs. Agentic RAG
Traditional RAG follows the straightforward three-step loop described above: retrieve, then generate. It works well for simple question-answering but has limitations. What happens when the first retrieval doesn’t return good results? Traditional RAG just pushes forward with whatever it finds.
Agentic RAG adds a reasoning layer on top.
An AI agent decides how to handle each query. It can change the search, link several retrievals, pick a knowledge base, or skip retrieval completely. Think of Traditional RAG as a student who looks up one page and writes their answer. Agentic RAG is like a student. They check several sources. They re-read sections that seem off and cross-reference information before writing.

Multi-Step RAG Pipeline
Production RAG systems often go beyond the simple retrieve-and-generate loop. A multi-step pipeline adds intelligence before and after retrieval:
Query Intent Parsing: Before searching, the system analyzes what the user actually wants. Is it a factual question? A comparison? A request for a summary? Understanding intent helps the system choose the right retrieval strategy and knowledge base.
Query Reformulation: The system may rewrite the user’s question to improve retrieval quality. For example, “Why is my app slow?” might become “application performance bottleneck causes and solutions.”
Retrieval: System searches for relevant chunks (as described above).
Live Web Search: If internal documents aren’t enough, some RAG systems can do live web searches. This helps them get current information from the internet.
Reranking22 and Filtering: Results are scored, filtered, and reranked for relevance.
Generation: LLM produces an answer grounded in all the gathered context.
This multi-step approach is what separates demo-quality RAG from production-quality RAG.
RAG Limitations
RAG is powerful, but it’s not a silver bullet…
Understanding its limitations helps you decide when to use it and when to look elsewhere:
Keep reading with a 7-day free trial
Subscribe to The System Design Newsletter to keep reading this post and get 7 days of free access to the full post archives.
 | A guest post by
|