
29 LLM Evaluation Concepts Every Engineer Needs to Know
#142: From “it looked fine in testing” to a system you can actually trust


Share this post & I'll send you some rewards for the referrals.
You ship an LLM feature.
It passes your manual tests. A day later, a user posts a screenshot of it hallucinating wildly! You tweak the prompt, run it again, and it works fine. Did you fix it, or did you just get lucky?
Welcome to the central frustration of LLM engineering: you can NO longer just run a test and call it done.
This isn’t a debugging problem…
It’s a measurement problem. And measurement has a name: evaluation.
Most articles on LLM evaluation are written for ML researchers. This one is for engineers building real applications. You know how to ship software. You’re just new to the ways LLMs fail.
We’ll cover the vocabulary, methods, and mental models. By the end, you’ll have a framework for building an eval system from scratch. Not just an understanding of why it matters.
Let’s start with why your existing testing instincts don’t work here…
Your team’s second brain. Now in Slack. (Partner)

Your engineers talk on Slack. They code in the terminal. Somewhere between those two things, context goes to die.
A bug was debated in #incidents at 2 AM.
An architectural call was made in a DM.
Every handoff leaks context, and every leak costs you. That’s the context tax - and your team pays it every day.
CodeRabbit Agent for Slack is built for agentic SDLC workflows. One agent for your entire Software Development Lifecycle, living in the channel where the work already happens. It’s built on four things:
Context - your org’s operating picture, pulled from across code, tickets, docs, monitoring and cloud.
Knowledge Base - a living memory of your team. Every run leaves a trace, so yesterday’s decisions don’t become tomorrow’s debates.
Multi-Player - works in shared threads alongside your team. Steerable, resumable and aligned as work evolves.
Governance - scoped access, cost attribution. Every run explainable and attributed.
Your team keeps shipping. Agent keeps the context.
From the team that pioneered AI code reviews. 2M code reviews every week. 6M repos. 15K customers. And now, one agent for your entire SDLC, right in Slack.
(Thanks to CodeRabbit for partnering on this post.)
I want to introduce Anshuman as a guest author.

He leads evals efforts at Zomato, where he built Gavel -- an internal LLM eval platform that started as a handful of scripts, got pitched to a VP, and now serves AI and ops teams across the company. Now he’s on the ground floor of making a large organization AI-native, one eval system at a time.
I highly recommend you checkout his newsletter, AI Proof -- it’ll help you stay relevant in the AI era.
Before we get into solutions, you need to understand something…
LLM evaluation feels nothing like regular software testing. It’s not that it’s harder. It’s that the rules changed.
Let’s dive in!
1. Non-determinism Problem
Write a function.
Call it with the same input twice, and you’ll get the same output twice.
But LLMs don’t work that way.
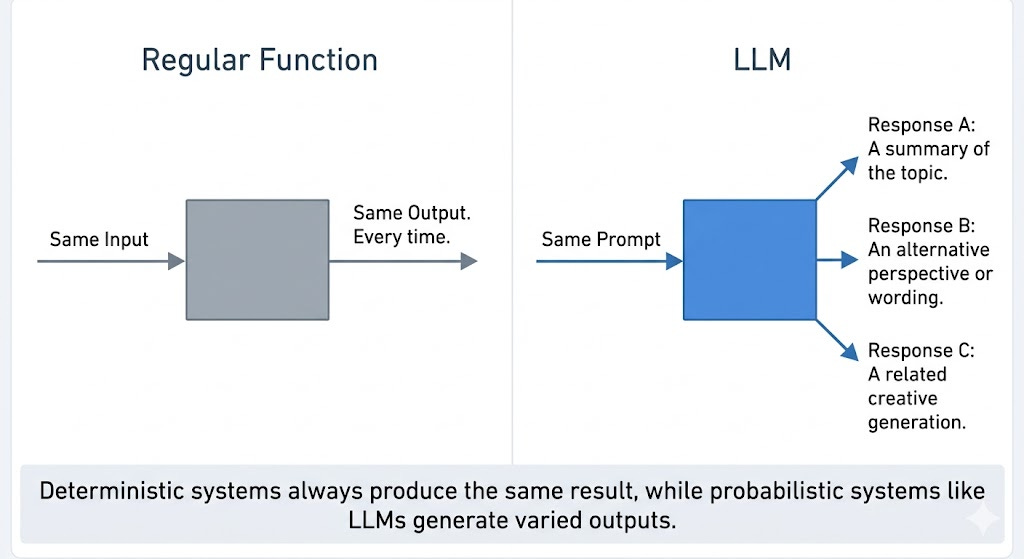
The same prompt can produce a different response on every run.
Sometimes slightly different. Sometimes completely different. This isn’t a bug. It’s called temperature.
It controls how random the outputs are. (More on this later.)
This breaks something deeper. Your entire mental model for testing assumes determinism. You run a test. It passes or fails. You know what you know.
With LLMs, a passing test is a data point, not a verdict. You’re not testing a function. Instead, you’re sampling from a probability distribution. One sample tells you almost nothing.
This is the first reason your existing instincts mislead you.
2. Fuzzy Correctness Problem
When a regex matches, it matches. Binary. Objective. Done.
But what’s the correct response to “summarize this support ticket empathetically?”
Is the correct answer the one that’s most concise?
The one that uses the warmest language?
The one that captures all the key facts?
The one a human reviewer would score highest?
LLM quality is multi-dimensional and subjective.
There usually isn’t one correct answer. There’s a range of acceptable answers and a range of bad ones. The line between them is a judgment call.
You can’t measure what you haven’t defined.
What does ‘good’ mean for your use case? You need a clear answer to that before you can evaluate anything. Most people skip this step. It comes back to haunt them.
3. Silent Regression Problem
You updated your prompt.
Ran it a few times. The outputs seemed better. You shipped it.
But did quality actually improve, or did you get lucky with the samples you checked?
This is the silent regression problem. Without a systematic evaluation process, every prompt change is a blind bet. You might be making things better. You might be fixing one failure mode while introducing another. And you have no way of knowing.
In traditional software, CI (Continuous Integration) catches regressions before they reach users. In LLM engineering, there’s NO such equivalent. So people rely on their gut feelings and manual spot checks. You find out about regressions when a user complains!
These three problems make LLM evaluation its own discipline…
Now let’s build the vocabulary to actually talk about it…
Primitives of Eval
These are six terms you’ll hear constantly.
Learn these, and the rest falls into place:
4. Criteria
Criteria are the dimensions of quality that matter for your specific use case.
A customer support bot might care about:
Does it address the user’s actual issue?
Is the tone empathetic?
Does it avoid triggering escalation unnecessarily?
A code generation tool cares about something completely different:
Is the output syntactically valid?
Does it follow the project’s conventions?
Does it actually solve the stated problem?
Same technology, but entirely different criteria.
This is a product decision, NOT a technical one. You can’t outsource it to your model or your eval framework. Someone on your team needs to sit down and answer: What does a good output actually look like here?
Get this wrong, and everything downstream is measuring the wrong thing…
5. Quality Dimensions
Quality dimensions are the standard industry vocabulary for LLM output quality.
Here are five of them that come up constantly:
Relevance: Did the output address what was actually asked? A response can be accurate, well-written, and completely beside the point.
Coherence: Does it hold together logically? No contradictions. No mid-sentence topic shifts. Flows like something a thoughtful person wrote.
Factual Accuracy: Is what it says actually true? Distinct from relevance. A response can be relevant and wrong.
Helpfulness: Does it give the user what they need to move forward? The difference between a technically correct answer and a useful one.
Safety: Does it avoid harmful, biased, or inappropriate content? This dimension matters more in some domains than others -- but it always matters.
Knowing these helps you write rubrics that don’t miss important failure modes.
6. Rubric
Once you have the criteria, you need to operationalize them.
That’s what a rubric does.
Take a vague criterion like “helpfulness.” A rubric breaks it into specific, scorable questions. Does it directly answer the question? Does it avoid unnecessary hedging? Is it under 200 words? Can a non-technical user understand it?
Think of it like a code review checklist.
Instead of “Is this good code?”, a checklist asks: Are there tests? Is the function under 30 lines? Are variable names descriptive? Rubrics do the same thing for LLM outputs.
The rubric is what makes evaluation reproducible.
Two different reviewers, human or AI, should arrive at similar scores. Same output, same rubric, same conclusion.
Without a rubric, every evaluation is just someone’s opinion.
7. Test Cases
A test case is an input/output pair that forms one unit of your evaluation.
Input is a prompt: ideally, one representative of real user traffic.
Output can be one of two things. A reference answer showing what good output looks like. Or the live model output you’re about to score.
Think of test cases like unit tests…
Except that a failing test case doesn’t mean the output was wrong. It means it scored below your defined threshold on your rubric.
That distinction matters.
You need a lot of them. A handful of test cases gives you anecdotes. A few hundred gives you a signal.
8. Golden Set
Everything in your eval gets measured against one thing: your golden set.
A curated collection of high-quality test cases.
Building a good golden set is harder than it sounds:
The instinct is to write examples yourself, covering the use cases you anticipate. That’s a start. But users phrase things differently than you expect. They hit edge cases you didn’t imagine.
And they might misuse features in creative ways.
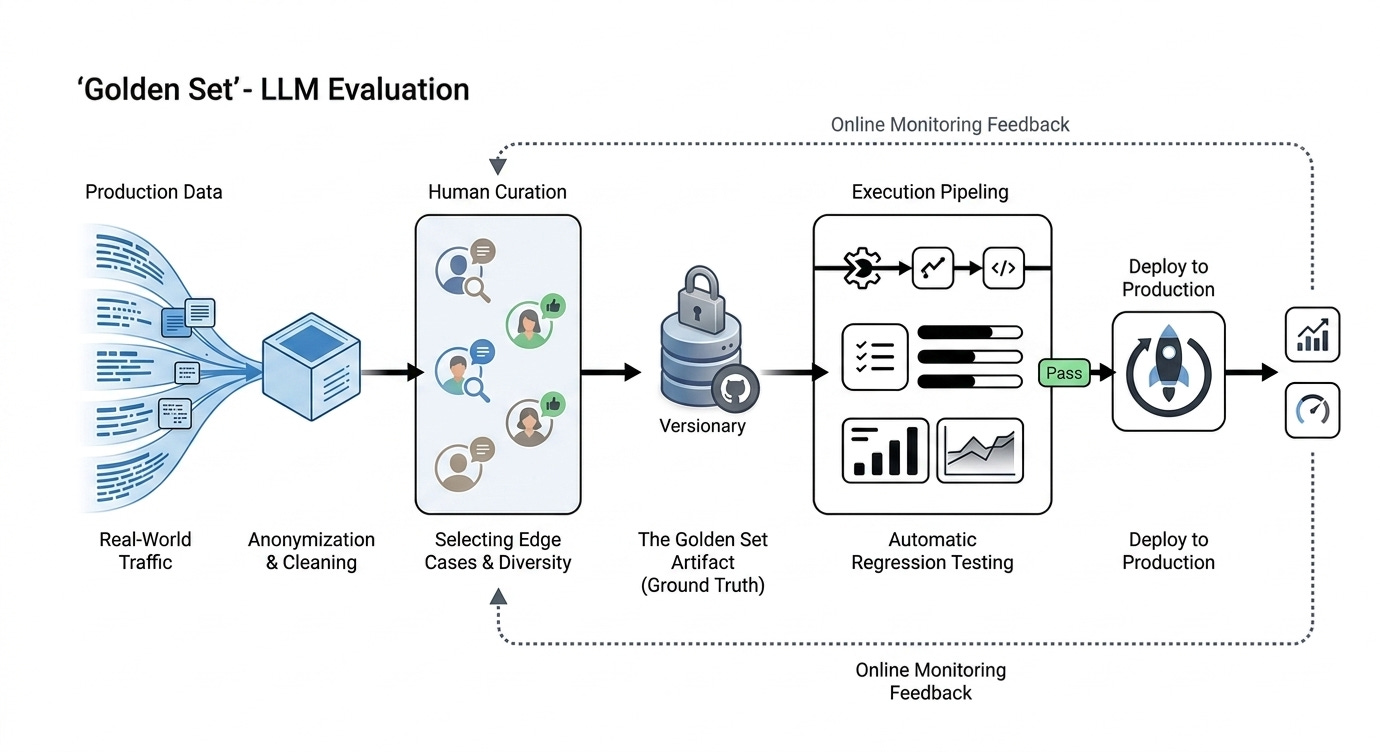
A golden set built from your imagination reflects your imagination and not your users’. So seed it with real production queries instead. Anonymized, cleaned, representative.
Your golden set is your ground truth.
Treat it like a critical system artifact. Version and update it when you discover new failure modes.
9. Pass/Fail Threshold
Eval scores are rarely binary.
A rubric usually produces a score of 1 to 5, 0 to 10, or a percentage. The pass/fail threshold is what converts that score into a decision.
If your rubric scores range from 1 to 5 and your threshold is 3, any score below 3 is a failure. Simple in theory, but HARD in practice.
Setting the right threshold is a product call, not a technical one.
It depends on a few things: how much imperfection your users can tolerate. How severe are failures in your domain? The cost of false positives.
Set your threshold too low, and you’re shipping garbage. And if you set it too high, you’re shipping nothing.
10. Eval Coverage
Eval coverage is how well your golden set reflects real user inputs.
Most teams have low coverage and don’t know it. They built their golden set from examples they had written. Happy path, a few obvious edge cases. Meanwhile, production traffic is different: weird inputs, unusual phrasings, use cases nobody anticipated.
Low coverage means your eval suite is optimistic…
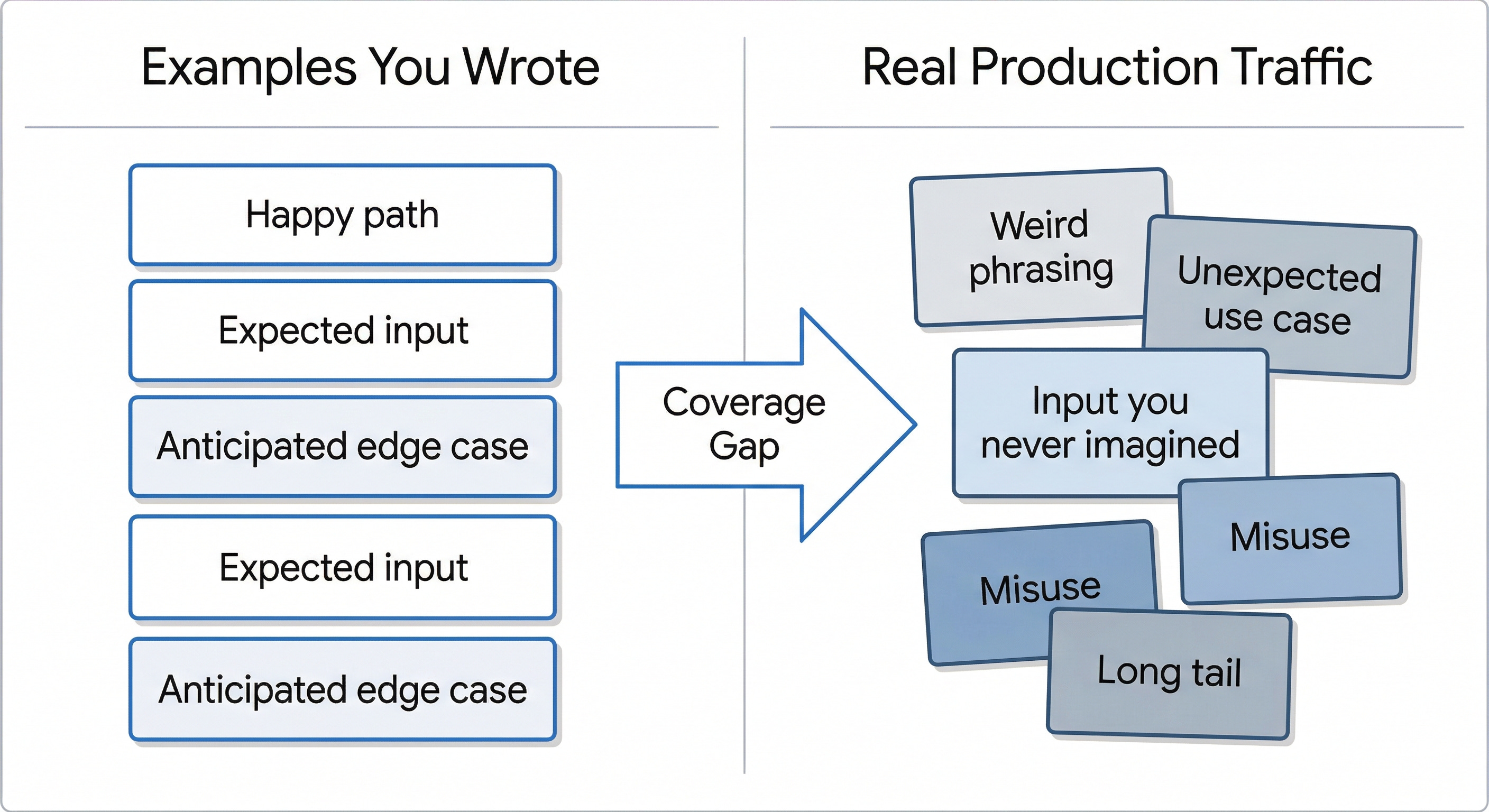
i.e., you’ll pass your tests but fail your users.
The fix isn’t writing more examples yourself. Instead, sample from production regularly and review failures. Then add the inputs that exposed new weaknesses to your golden set.
Eval coverage is something you build over time.
11. Temperature, Top-p, and Reproducibility
Temperature is the dial that controls how random your model’s outputs are.
Low temperature (close to 0) makes the model nearly deterministic: same input, same output, every time. High temperature makes it more creative. It samples from a wider range of probable tokens, producing more varied responses.
Top-p (nucleus sampling) is a related setting.
Instead of a randomness dial, it sets a probability cutoff. Only the most likely tokens make the cut. Top-p = 0.9 means the model considers only the top 90% most likely next tokens.
Both settings directly affect your eval results…
Run evals at temperature = 1.0 and the same prompt might pass today and fail tomorrow. NOT because your model changed, but because randomness swung against you.
Here’s the standard practice: set temperature to 0 during eval runs. And lock in determinism. If you need creative variance in production, test at your production temperature.
Just know you’re accepting noisier results…
12. Statistical Rigor
Even at temperature = 0, a single eval run isn’t enough.
Your golden set is a sample of your input space. That sample has its own variance. One unlucky set of examples can make a good prompt look bad. And one lucky set can make a bad prompt look good.
So run many evaluations across different samples.
Then report the mean and the variance, not just the score. When comparing two prompt versions, check whether the difference is real. Or if it’s just noise.
In practice: if you change a prompt and your score goes from 4.1 to 4.3, that might be a real improvement.
It might be a random fluctuation. Without variance1 data across many runs, you can’t tell the difference. Most teams run once, report the number, and ship. That’s how confident regressions get deployed…
How Do You Score Outputs?
You have criteria, a rubric, and test cases2.
Now the question is: who does the scoring? There are three options.
Each has different tradeoffs in cost, speed, and accuracy.
13. Human Evaluation
This is the gold standard.
A human reviews the output using your rubric and gives a score. It’s slow, expensive, and can be inconsistent. But it’s the closest thing to ground truth.
You can’t use humans for every eval run; it doesn’t scale.
But you shouldn’t remove human evaluation completely either. It’s what keeps your system grounded. Everything else: metrics, LLM judges, tests, is just an approximation of human judgment.
So use human evaluation strategically:
To build and validate your golden dataset.
To periodically check the accuracy of your automated evals.
To debug when something breaks and you don’t know why.
This way, you balance cost with reliability.
14. Heuristic/Code Based Evaluation
This is the fastest and cheapest type of evaluation.
It uses simple code checks to validate the output's structural properties. For example:
Is the response valid JSON?
Is it within the character limit?
Does it include all required fields?
Does it avoid banned phrases?
Does it match a specific format (like a regex)?
Heuristic eval is good at catching structural problems.
But they don’t measure quality. They can’t tell if a response is helpful, accurate, or well-written.
Think of heuristics as your first line of defense.
They catch basic issues before you run more expensive evaluations. They’re NOT enough on their own, but they’re an essential part of a complete eval system…
15. Semantic Similarity Evaluation
Sometimes you have a reference answer, a known-good response representing ideal output.
Semantic similarity evaluation measures how close your model’s output is to the reference. i.e., in meaning, and not exact wording.
This is where embeddings come in…
Each piece of text gets converted into a vector: a list of numbers that represents its meaning. Texts with similar meanings have vectors that are close to each other. Cosine similarity measures the angle between two vectors. A score of 1.0 means identical meaning. A score near 0 means unrelated.
This matters because string matching is too strict.
Take two sentences: “API returns a 404 error” and “Endpoint responds with a not found status.” They mean the same thing, but use different words. An exact match would call the second one wrong. Semantic similarity would call them equivalent.
But here’s the limitation: it only measures closeness to your reference.
It can’t catch a response that’s fluent and factually wrong. Not if the wrong answer happens to be semantically similar to the right one. So use it as a fast, scalable layer. And don’t rely on it alone!
16. Task Specific Metrics (BLEU, ROUGE, Execution-based)
For certain tasks, there are established metrics purpose-built for automated evaluation:
BLEU (Bilingual Evaluation Understudy): Originally for machine translation. Measures n-gram overlap between generated text and a reference. Good for tasks where exact phrasing matters.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation): Designed for summarization. Measures recall: how much of the reference answer appears in the output? Useful when you care about coverage: did the model hit all the key points?
Execution-based evaluation: For code generation, one metric matters. Does it run? Does it produce the correct output? Execution-based eval runs the generated code against test cases and checks the results. A function that returns the wrong answer fails. Another function that passes all tests succeeds.
But all three share the same trade-off:
They measure surface-level similarity to a reference, not actual quality. So use these where they fit.
17. LLM as Judge
This is what makes evaluation scalable…
LLM-as-judge uses a more capable model to evaluate your application’s outputs. You give it three things:
Original input,
Output you’re evaluating,
Your rubric.
The judge then returns a score and an explanation.
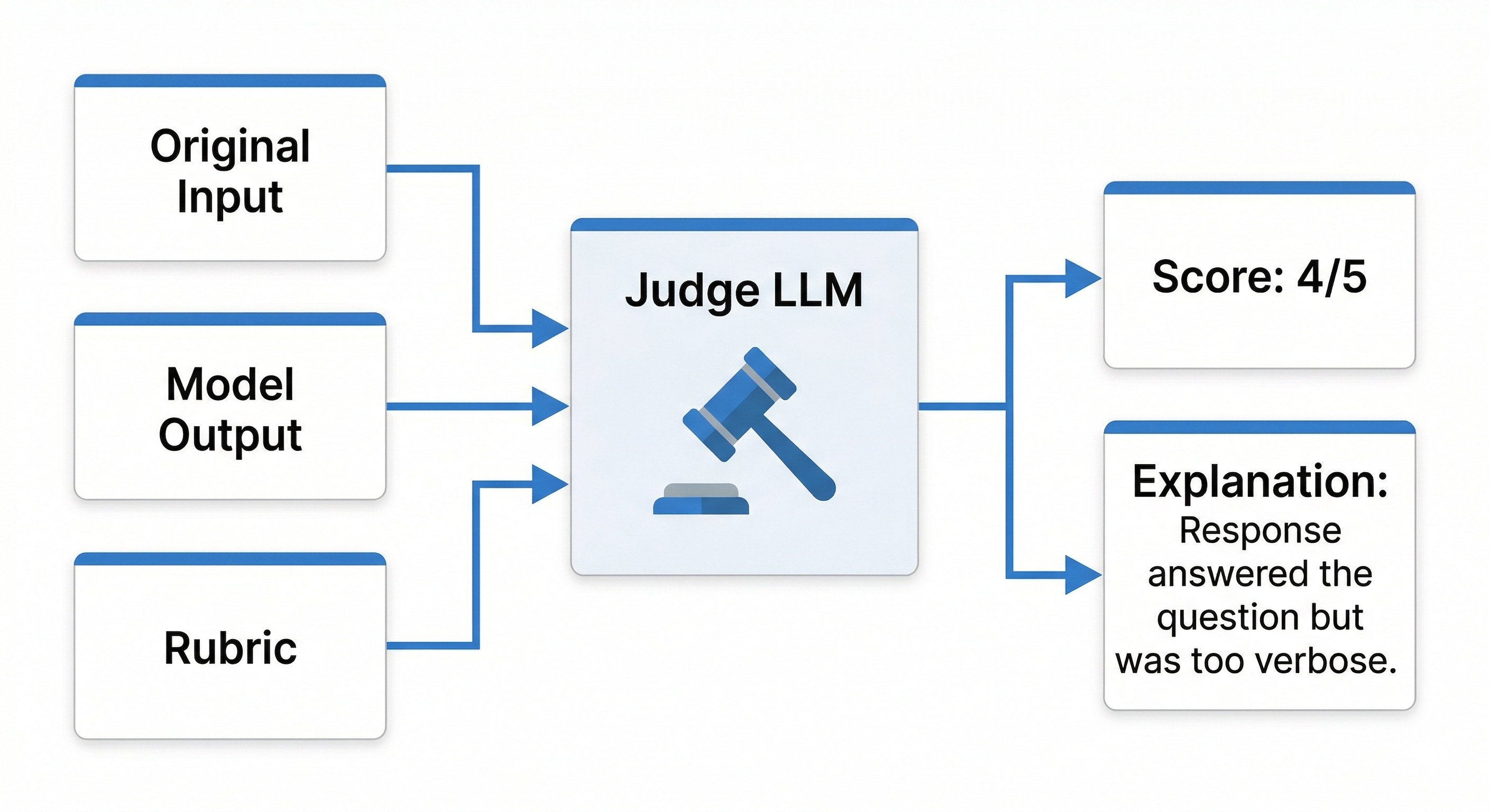
Think of it like automated load testing.
Nobody clicks through 10,000 user flows to check for regressions. You can instead automate it. LLM-as-judge does the same thing for quality. It lets you run your rubric across thousands of outputs without thousands of human hours.
GPT-5 and Claude Opus are commonly used as judges. They’re capable enough to apply nuanced rubrics reliably. You’re calling them via API, NO custom training required.
But here’s the catch: judges can be wrong.
They have their own biases and blind spots. An LLM judge is an approximation of human judgment, not a replacement for it.
More on how to handle this in a moment…
18. Pointwise vs Pairwise Evaluation
These are 2 flavors of LLM-as-judge evaluation:
Pointwise
You ask, “Score this output on a scale of 1–5.”
It’s simple and fast.
And each output needs one evaluation call.
Pairwise
You ask: “Here are two outputs. Which one is better?”
This is usually more reliable because comparing is easier than scoring.
It’s especially useful when you want to know if a new prompt is actually better.
But the downside of pairwise is the cost…
You’re evaluating two outputs instead of one, so it can be twice as expensive. At a small scale, this doesn’t matter, but at a production scale, it adds up quickly.
Because of this, the industry standard is to use a tiered approach:
Online evaluation (production monitoring)
Use fast, cheap methods like heuristics or smaller, fine-tuned judge models.
These can run continuously without high cost or latency.
Offline evaluation (pre-ship testing)
Use the best LLM judge you have.
Run pointwise and pairwise comparisons.
This is acceptable because you’re only running it before deployments.
Think of the powerful judge model as a gate before deployment, and NOT something you run on every request.
19. Judge Calibration
Before you rely on an LLM judge, you need to know how well it matches human judgment…
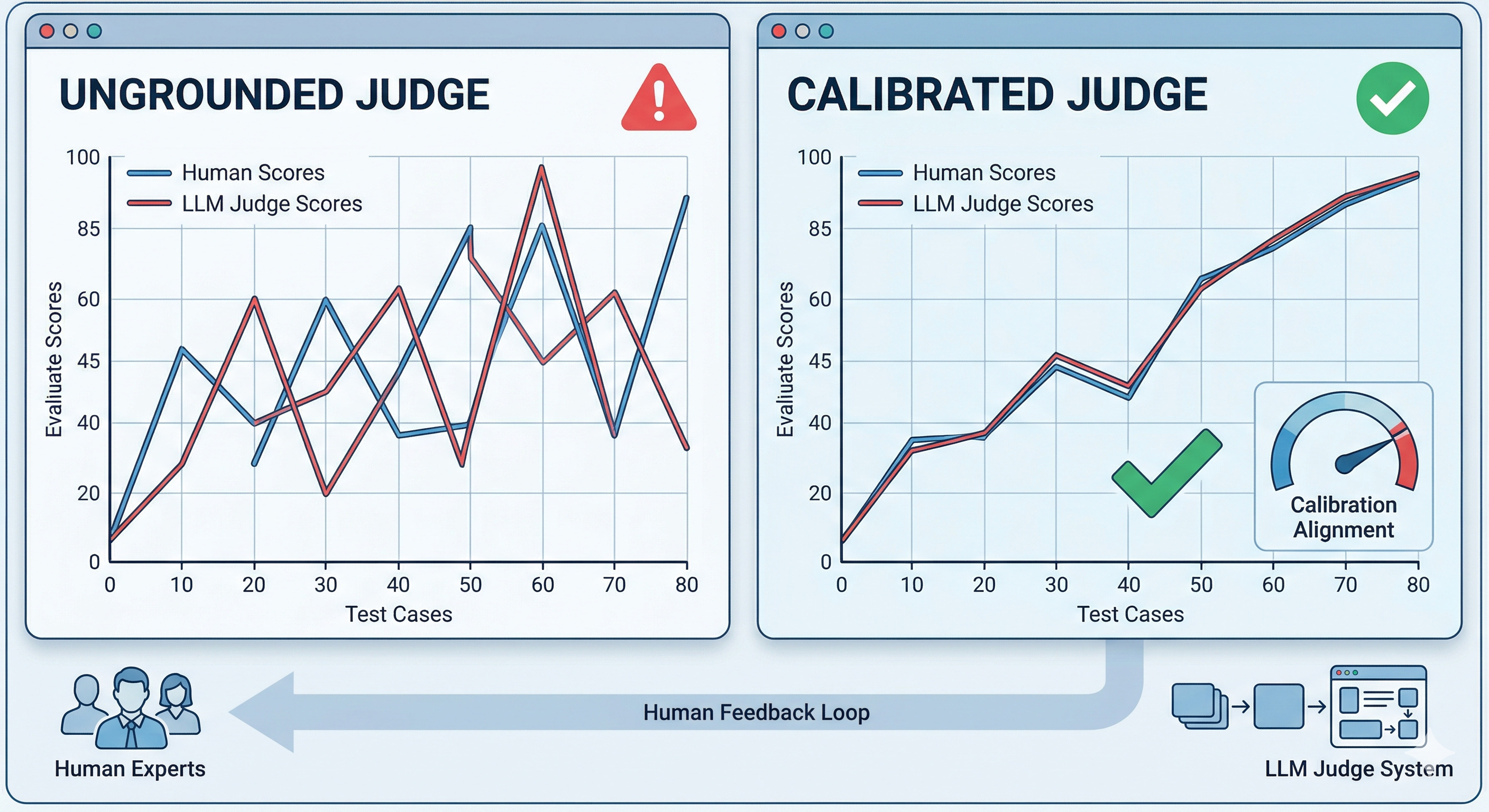
Judge calibration measures this:
You take a sample of outputs, have both humans and the judge score them, and then check how often they agree.
If agreement is high, your judge is a good proxy for human evaluation.
If agreement is low, the judge may be measuring the wrong thing.
A poorly calibrated judge is risky.
It can give you confidence in results that aren’t actually correct. So calibrate your judge before using it. Then recalibrate periodically, especially after changing models or prompts.
Get 20% savings by getting a group subscription right now:
RAG System Evaluation
Most LLM applications today aren’t just “prompt in, response out.”
They use Retrieval-Augmented Generation (RAG): first fetch relevant documents, inject them into the context, and then generate a grounded response.
This helps reduce hallucinations because the model can rely on real data rather than just its training data. But it doesn’t solve the problem completely…
It also introduces new failure modes that standard LLM evaluation doesn’t catch…
20. RAG Triad
The standard framework for evaluating RAG systems has three dimensions:
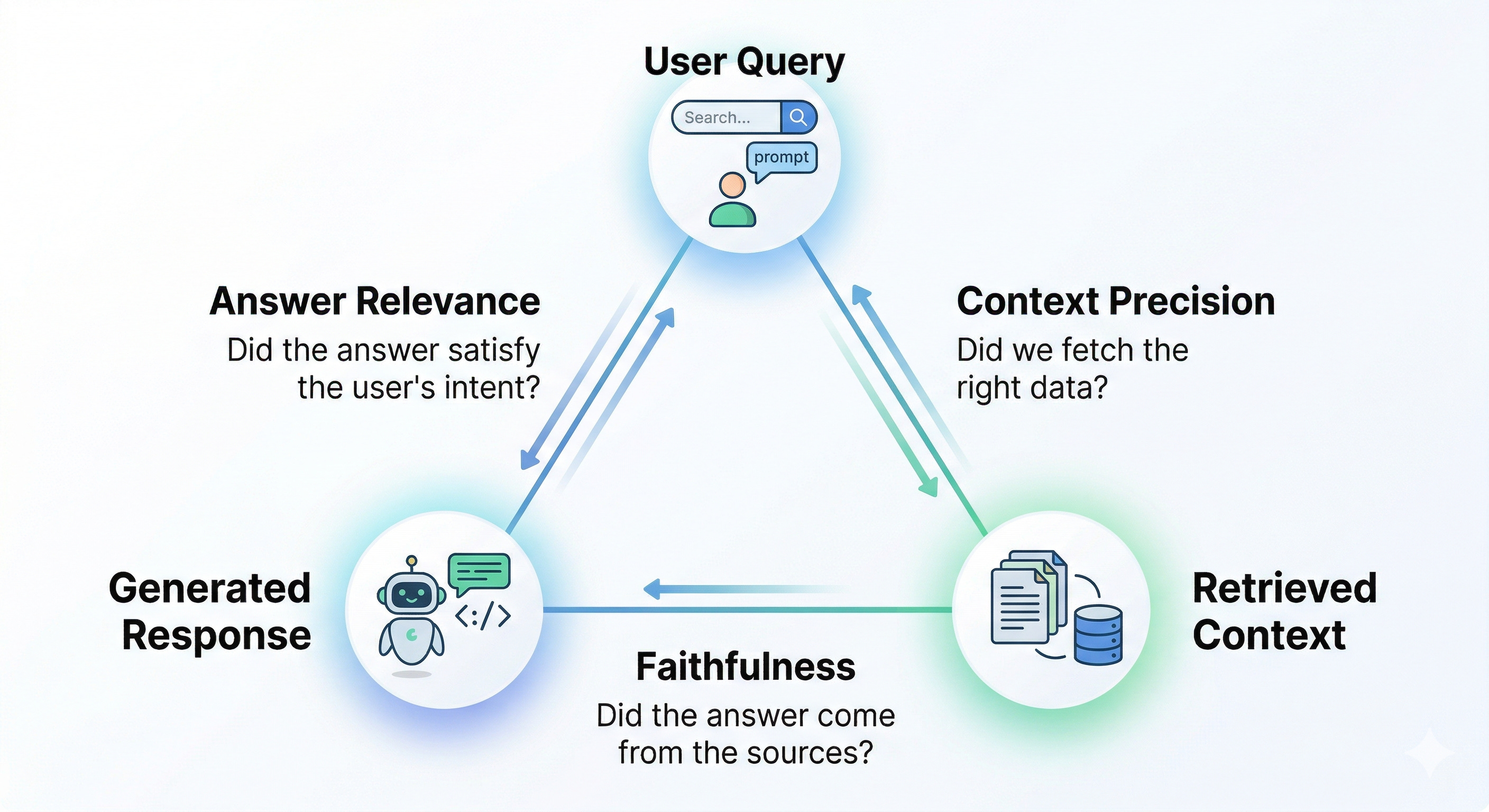
1 Faithfulness
Did the answer actually come from the retrieved context?
This often surprises people. You can retrieve the perfect documents, and the model can still ignore them. Faithfulness checks whether the response is grounded in the provided sources.
A failure here looks like a confident answer that isn’t supported by the retrieved documents. So it’s just a hallucination with extra steps.
2 Answer Relevance
Did the response actually answer the user’s question?
A response can be faithful to the context and still miss the point. The model may use the right documents but answer the wrong question.
Answer relevance measures how well the response matches the user’s intent. While Faithfulness checks if the model stayed within the context.
3 Context Precision
Did the retrieval step fetch the right documents?
Even a perfect generator will fail if the input context is poor. If retrieval brings in weak or loosely related documents, the model either guesses or tells the user it doesn’t know.
Context precision evaluates the retrieval stage. It checks how many of the retrieved documents were actually relevant.
Think of a RAG system as three stages: retrieval, augmentation, generation.
Each stage can fail on its own… The RAG triad is your observability layer to isolate where the problem is, so you know what to fix.
21. RAG-Specific Failure Patterns
Understanding the RAG triad is one thing. Spotting failures in practice is another…
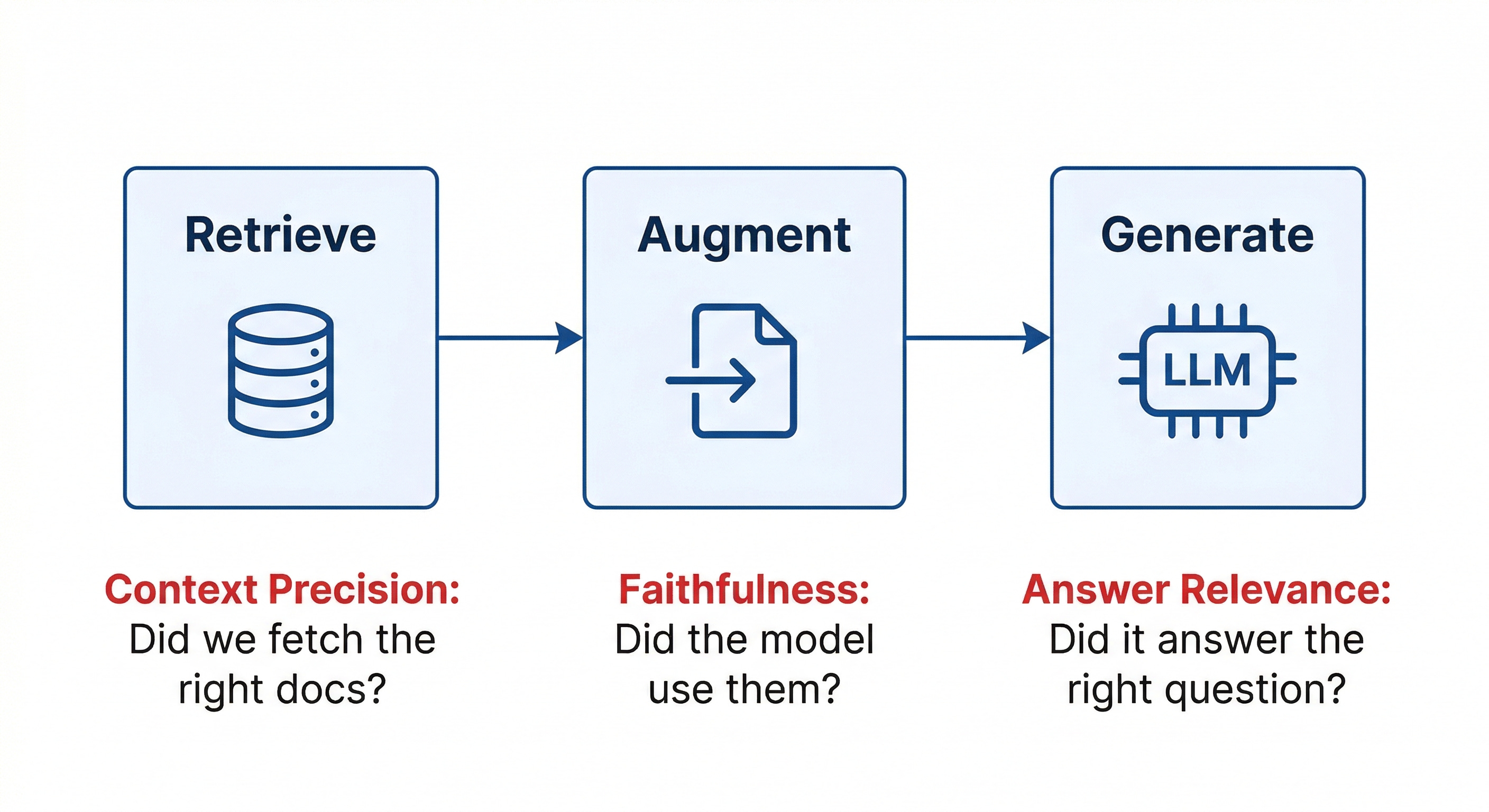
Here are the three most common failure patterns:
1 Retrieval returns irrelevant chunks (Context precision failure)
The system retrieves the wrong or loosely related documents. And the model then either:
Hallucinates to fill the gaps,
Or says it doesn’t have enough information.
The fix is in your retrieval layer: embedding quality, chunking strategy, re-ranking.
2 Retrieval is correct, but the model ignores it (Faithfulness failure)
The right documents get retrieved, but the model doesn’t use them.
This is usually a prompting issue. The model isn’t being forced to rely on the provided context. The fix is to strengthen the prompt, so the model stays grounded to the sources.
3 The answer is grounded but doesn’t help the user (Answer relevance failure)
The answer is technically correct and grounded, but doesn’t solve the user’s problem. This usually means your knowledge base is missing the right information. The fix is to improve or expand your data, NOT your prompt.
Get 20% savings by getting a group subscription right now:
Offline vs Online
Scoring a single output is one problem.
Building a system that reliably catches failures (before and after deployment) is another. There are two environments where evaluation happens:
22. Offline Evaluation
Offline evaluation happens before you ship.
You make a change: a new prompt, model version, or retrieval strategy. Before it reaches users, you test it against your golden dataset. Then you score the outputs and compare them to your current system.
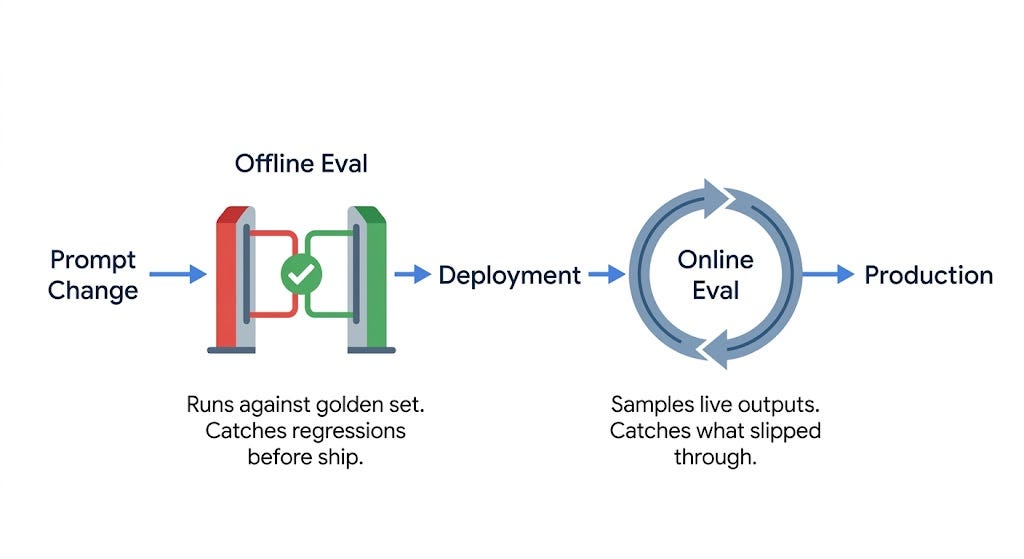
Think of this like a continuous integration (CI) pipeline for LLMs.
A change shouldn’t go live unless it passes your evals. If quality drops, you catch it before deployment.
Plus, this is where you use your best (most accurate) judge model. For example, GPT-5, Claude Opus. Cost matters less here because you’re only evaluating a finite set of examples, and NOT each user request.
23. Online Evaluation
Online evaluation occurs in production.
You’re sampling live outputs continuously and scoring them. The goal is to catch issues that offline evals miss: edge cases, unusual inputs, and failures that only appear at scale.
Think of online eval as your monitoring system…It helps you catch problems before users report them.
Yet the main constraint is cost. You can’t run your most expensive models on each request. So online eval relies on heuristics and smaller judge models; it’s cheap enough to run continuously.
This means you trade some accuracy for scale…
Offline and online eval should work together:
Offline eval catches known issues before deployment
Online eval catches unexpected issues in production
So you need both for a reliable system.
24. Prompt Versioning and Regression Testing
Your prompt is code; treat it that way.
Track every prompt change: use version control, keep history, and compare differences. When something breaks, you should know exactly what changed and when.
Without versioning, you’d NOT know what changed.
Regression testing means running your eval suite against each prompt version. If your old prompt scored 4.2 and the new one scores 3.8, you’ve introduced a regression and caught it before it reached users.
This sounds simple, but most people don’t do it. They lack a solid eval setup: no golden dataset, no clear rubric, no infrastructure.
This is what separates people who iterate confidently from people who ship & pray.
25. Benchmark-Based Evaluation
Benchmarks are standard tests used to compare different LLM models:
1 MMLU (Massive Multitask Language Understanding)
Tests knowledge across many subjects like math, science, law, and medicine. Think of it as a general knowledge exam for LLMs.
2 HellaSwag
Tests common sense reasoning. The model is given the start of a scenario and must predict what happens next. (Many earlier models struggled with this.)
3 HumanEval
Test code generation. The model gets a function signature and must write the correct implementation. It’s measured using pass@k: how often the model gets the right answer within k attempts.
Here are two useful leaderboards:
Hugging Face Open LLM Leaderboard for open-weight models
Chatbot Arena (LMSYS), where models get ranked based on human preferences
Remember, these benchmarks are useful for comparing models, but they don’t always reflect real-world performance for your specific use case…
26. Benchmark vs Real-World Tradeoff
Benchmarks don’t tell you if a model will work for your specific use case.
A model that scores 90% on MMLU might still struggle with your domain-specific language. A model that performs well on HumanEval might generate code that doesn’t fit your standards… Benchmarks measure general capability, but your application might need a specific capability.
So use benchmarks to narrow down your options. Then use your own eval on your own golden set to make the final decision.
27. Dataset Contamination / Data Leakage
There’s a problem with benchmarks that most engineers overlook:
Dataset contamination occurs when evaluation data overlaps with the model’s training data. The model has already seen the answers. So its high benchmark score reflects memorization, NOT capability.
This happens because training data and benchmark datasets come from the internet. And the data overlap is often unknown. Over time, widely used benchmarks become less reliable, which is why new ones keep getting created…
To avoid this, don’t rely on public examples for your evals…Plus, use real user queries and create your own datasets instead.
Failure Modes (What Not to Do)
You can have the right tools and still build a BAD eval system.
Here are the common mistakes:
28. Eval Anti-Patterns
Vibe-based evaluation.
“I tried it a few times, and it looked good.”
This is the most common mistake. Informal spot-checking creates false confidence. It doesn’t catch edge cases, track performance over time, or scale beyond one person looking at a few outputs.
Vibes are a starting point, but not an eval system.
The single-sample trap.
You run your eval suite once and report the results.
But LLMs are nondeterministic…
A bad prompt might look good
A good prompt might look bad
So run many samples and aggregate results. Remember, report variance, not just average scores.
Goodhart’s Law in disguise.
“When a measure becomes a target, it stops being a good measure.”
If you optimize for a metric too aggressively, the metric stops measuring what you care about…
Reward confidence: you’ll get confident hallucinations
Reward length: you’ll get long, low-quality answers
Metrics are only a proxy for quality. So don’t mistake them for the actual goal.
Eval-production mismatch.
Your golden dataset reflects what you expect.
Yet real users behave differently. They’re vague, unpredictable, and use your system in ways you didn’t anticipate. If your evals don’t reflect real usage, your scores are misleading. A high pass rate on unrealistic data doesn’t mean your system works.
Ignoring tail failures.
A 92% pass rate sounds good. But what about the 8%?
LLM failures are often catastrophic, not graceful. One harmful or incorrect response can matter more than hundreds of correct ones. So always review failure cases, not just averages.
The worst outputs tell you the most…
Get 20% savings by getting a group subscription right now:
Decision Framework
There’s no single tool that solves LLM evaluation.
What works is a layered system… Each layer catches problems the previous one misses…
29. Eval Stack
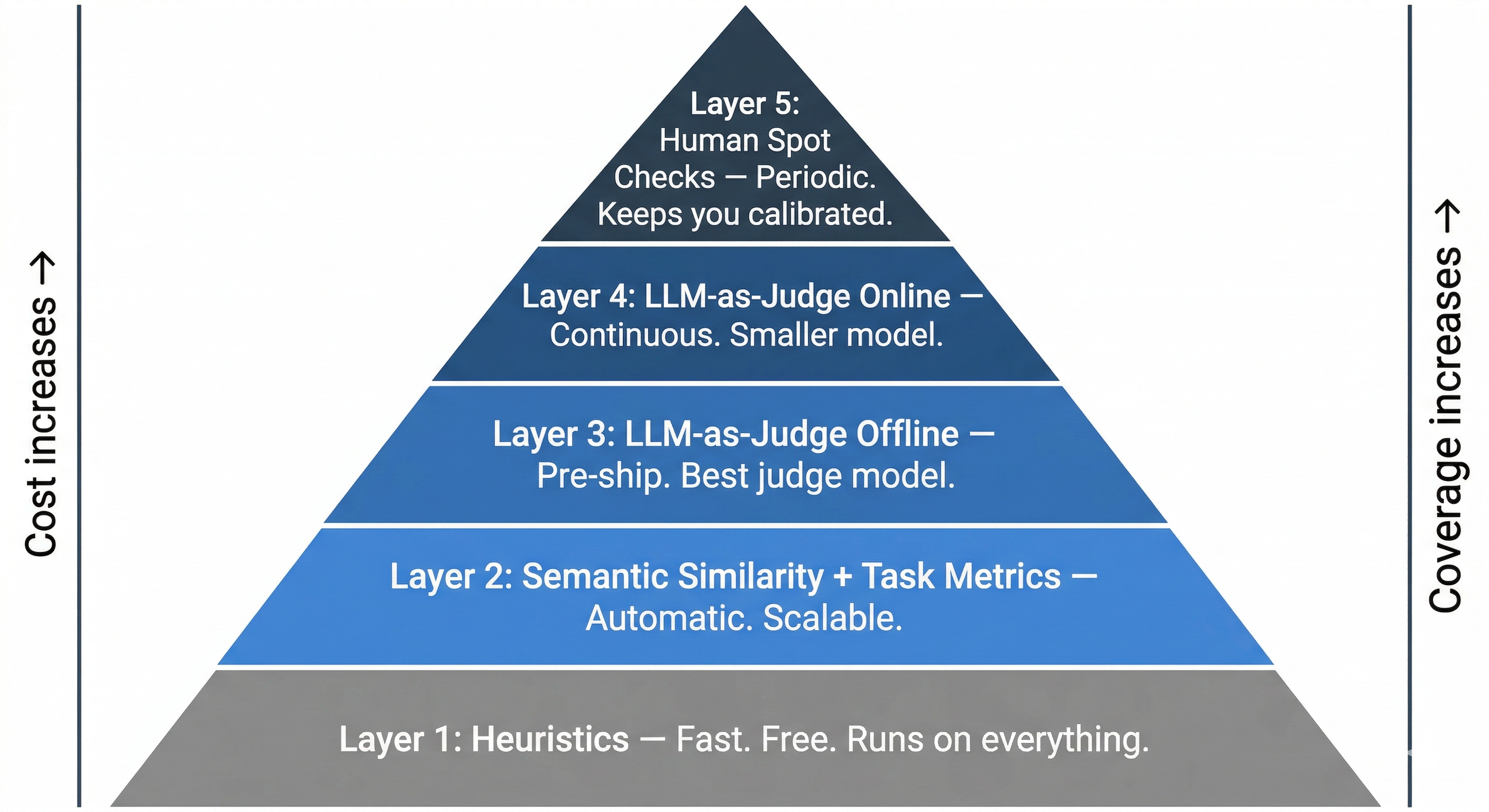
Layer 1: Heuristics.
Fast, deterministic, and cheap. These run on every output and catch structural issues such as incorrect format, missing fields, or banned content.
Layer 2: Semantic similarity and task-specific metrics.
These run automatically against reference answers. They help catch meaning-level failures without the cost of an LLM judge.
Layer 3: LLM-as-judge (offline).
This runs before deployment on your golden dataset using your best judge model. Its job is to catch quality regressions before they reach users.
Layer 4: LLM-as-judge (online, smaller model).
This runs in production on a sample of live outputs using a smaller, cheaper judge model. It helps catch failures at scale that offline evals missed.
Layer 5: Human spot checks.
These run periodically. And keep you calibrated, verify automated evals scoring still match human judgment, and add new failure cases back into your golden dataset.
Each layer has a different cost profile and catches a different failure type…
Eventually, you want all five. But you do NOT need all of them on day one.
So if you are starting from scratch, here is a simple three-step MVP:
Step 1: Build a golden set of 50 examples.
Don’t write all of them yourself.
Use real user queries if you have them. If not, create 30 representative examples and 20 edge cases. Also, include normal cases, adversarial inputs, and strange phrasings you expect users to try.
This dataset becomes the foundation of your eval system.
Step 2: Add one deterministic heuristic.
Pick the single most important structural requirement for your output.
That might be length, format, a required field, or a banned phrase. Then write a simple code check for it. This is quick to build and catches more failures than most people expect.
Step 3: Add one LLM judge prompt.
Take your rubric and turn it into a judge prompt.
Then use a strong model to score outputs on one important quality dimension, and run it on your golden dataset. Read the scores and the explanations carefully.
You will find something surprising…that’s the point.
That is your MVP eval system.
Everything else builds on top of it: pairwise comparisons, online monitoring, RAG scoring, regression testing, and more.
Start here…
Closing Thoughts
Evaluation isn’t something you do at the end.
Instead, it’s what makes iteration possible. Without it, you’re not doing LLM engineering. But guessing and shipping changes, only to find out from users that they didn’t.
Traditional software engineering learned this lesson the hard way: CI, automated tests, production monitoring…these aren’t optional. They’re what make fast, reliable development possible.
LLM systems need the same discipline. The difference is that the outputs are nondeterministic and hard to measure.
Now you have the vocabulary to deal with that…
Start simple and build your eval stack step by step. Over time, you’ll know whether a change improved quality before users ever see it.
👋 I’d like to thank Anshuman for writing this newsletter!
If you’re building LLM applications and want to go deeper, follow him on LinkedIn and X.
Don’t forget to check out his newsletter, AI Proof -- it’ll help you stay relevant in the AI era.
Louis and I launched the GENERATIVE AI MASTERCLASS (newsletter series exclusive to PAID subscribers) this month.
When you upgrade, you’ll get:
Simple breakdown of real-world architectures
Frameworks you can plug into your work or business
Proven systems behind ChatGPT, Perplexity, and Copilot
👉 CLICK HERE TO JOIN THE GENERATIVE AI MASTERCLASS
(Golden members will get the next Generative AI newsletter in the first week of May.)
If you find this newsletter valuable, share it with a friend, and subscribe if you haven’t already. There are group discounts, gift options, and referral rewards available.

Want to reach 200K+ tech professionals at scale? 📰
If your company wants to reach 200K+ tech professionals, advertise with me.
Thank you for supporting this newsletter.
You are now 210,001+ readers strong, very close to 210k. Let’s try to get 211k readers by 29 April. Consider sharing this post with your friends and get rewards.
Y’all are the best.

Variance is how much your results change when you repeat the same evaluation. It tells you how spread out or inconsistent your scores are.
Criteria: what you care about when judging the output (e.g., accuracy, clarity, helpfulness)
Rubric: how you score those criteria consistently (e.g., a 1–5 scale with clear definitions)
Test cases: specific inputs or examples that you use to evaluate the model
 | A guest post by
|
The deeper issue with LLM evals is that they force teams to admit something uncomfortable: most companies never really defined “quality” in the first place. With deterministic software, you could hide behind pass/fail tests. With LLMs, that illusion breaks. Now you have to decide what matters: accuracy, usefulness, tone, risk, latency, cost, refusal behavior, source faithfulness, user trust, business outcome. And those things often conflict.
Tools do not only change what we can do.
Over time, they also change what cognitive muscles we continue to practice using ourselves.