

How Meta Serverless Handles 11.5 Million Function Calls per Second
#94: Break Into Serverless Architecture

Download my system design playbook for FREE on newsletter signup:
This post outlines serverless architecture. You will find references at the bottom of this page if you want to go deeper.
Share this post & I'll send you some rewards for the referrals.
I created the block diagrams using Eraser.
Once upon at Meta, engineers wrote infrastructure code whenever they launched new services.
And some services did a ton of concurrent processing during peak traffic. (Think of scheduling notifications or thumbnail creation.)
Yet a pre-allocated infrastructure doesn’t scale dynamically.
So they decided to set up a function as a service (FaaS)1.

A FaaS is the serverless way to scale with increasing load.
It lets engineers focus only on writing code and handles infrastructure deployment automatically. Thus improving the engineer’s productivity.
Imagine FaaS as a job queue, but managed by someone else.
Onward.
Vision Agents: Build Real-Time Video + Audio Intelligence. Open Source. Open Platform. (Sponsor)

Vision Agents is a framework for building real-time, multimodal AI that can see, hear, and respond in milliseconds.
Built for developers who want to bring true intelligence to live video without being locked into a single model or transport provider.
Open Source: Fork it, read it, improve it.
Open Platform: Works with Stream Video or any WebRTC-based SDK.
Flexible Providers: Plug in OpenAI Realtime, Gemini Live, or your favorite STT/TTS and vision models.
Fully open, extensible, and ready for your next AI project.
It’s possible to build a hyperscale FaaS by adding many servers and putting a load balancer in front.
But this approach creates new problems.
Let’s dive in:
1. Cost Efficiency
Restarting a server is better than keeping it idle for low costs.
Yet a load balancer keeps servers running even if idle.
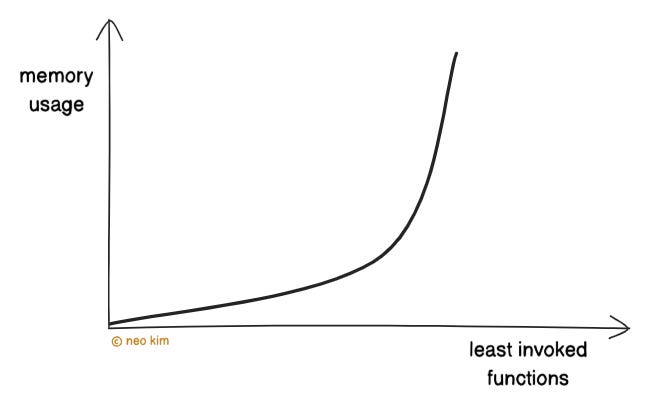
Besides:
81% of functions get invoked at most once per minute.4
And most functions run for less than a minute on average.
So this approach would cause high costs and waste computing resources. While an under-provisioned server would make a slow system.
They run functions in separate Linux processes for data isolation within the worker5. An idle Linux process doesn’t consume many resources.
But:
144 servers idle for 10 minutes → 1 server day WASTED.
144 servers idle for 10 minutes → 1 extra machine → same THROUGHPUT6.
At Meta’s scale7, they’d need 33,400 extra servers to achieve the same THROUGHPUT.
So it’s necessary to reduce server idle time. Otherwise, they’d lose money on hardware costs.
2. Latency
Servers crash. Also autoscaling8 adds new servers with varying traffic.
The creation of a new virtual machine to handle a request is called a cold start9.
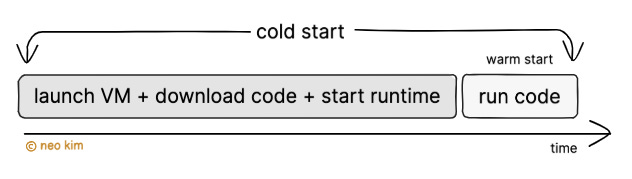
Yet a cold start takes extra time10 before it can serve the first request because it’s necessary to:
Start the virtual machine.
Download the container image and function code.
Initialize the container.
Initialize the language runtime and function code.
Do just-in-time (JIT) compilation11.
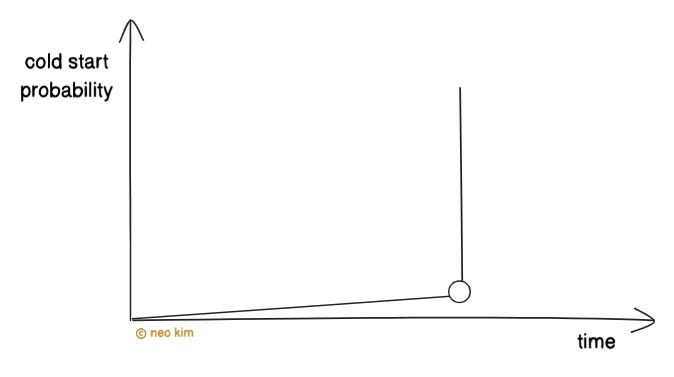
Also if the container gets shut down because a function isn’t used for a period, then it has a cold start problem again. Put simply, an early shutdown of the container causes latency because of re-initialization12.
3. Availability
Load spikes13 occur.
And this could overload the services that the function is calling. (Thus affecting system availability.)
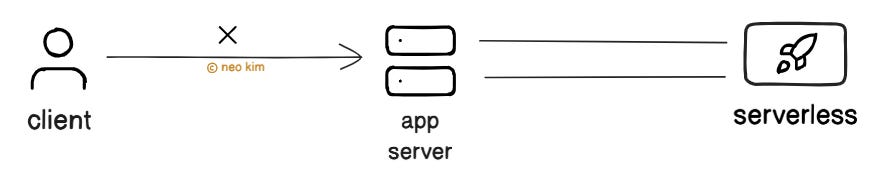
Also there might be high variance14 in load. So it’s necessary to:
Scale the serverless routing layer (discovery).
Process the functions reliably without causing retry storms15.
Besides handling errors gracefully during function execution is important.
Let’s keep going!
How Serverless Works
Building a serverless platform with high CPU utilization and low latency is hard.
So smart engineers at Meta used simple techniques to solve it.
Here’s how they built a hyperscale distributed operating system (XFaaS):
1. Cold Start
They run functions on a server called the worker.
And categorizes those workers into namespaces based on programming language. This ensures that each worker gets only compatible code and executes faster.
Also this technique gives extra security through physical isolation.
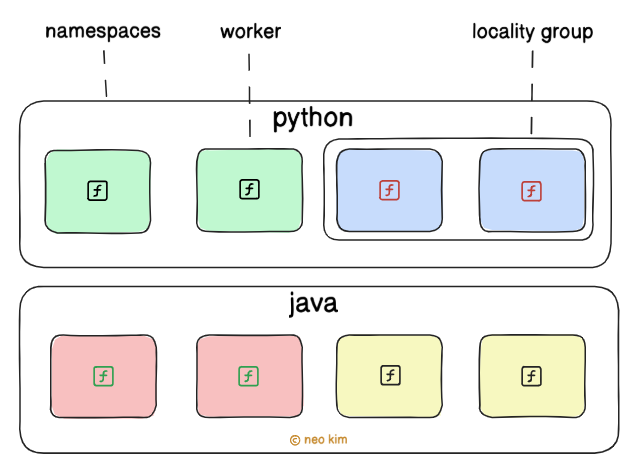
While a worker within a namespace can run any function written in that language to reduce cold start. This is called the universal worker model.
Yet each server doesn’t run every function, but only a subset of them. This approach keeps the JIT-compiled code cache small and efficient.
Also they form locality groups within a namespace by grouping workers that run the same functions often. This approach reduces memory usage and improves caching through better JIT code reuse.
Repeated downloads increase latency and waste network bandwidth.
So they pre-push the function code and container images onto the server’s SSDs. This avoids repeated downloads and keeps an always-active runtime.
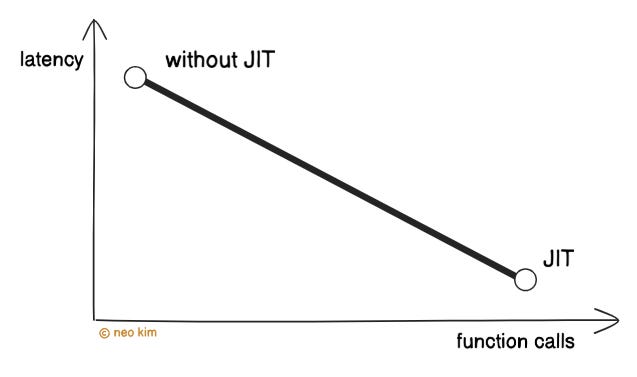
Besides they do cooperative JIT compilation for faster execution of functions. It means only specific workers compile new function code. Then those workers send the compiled code to ALL workers. Thus preventing redundant compilation overhead.
Ready for the next technique?
2. Backend Service Protection
There’s a risk of overloading the backend services that the function is calling during a load spike.
So they protect those services using backpressure-based throttling.
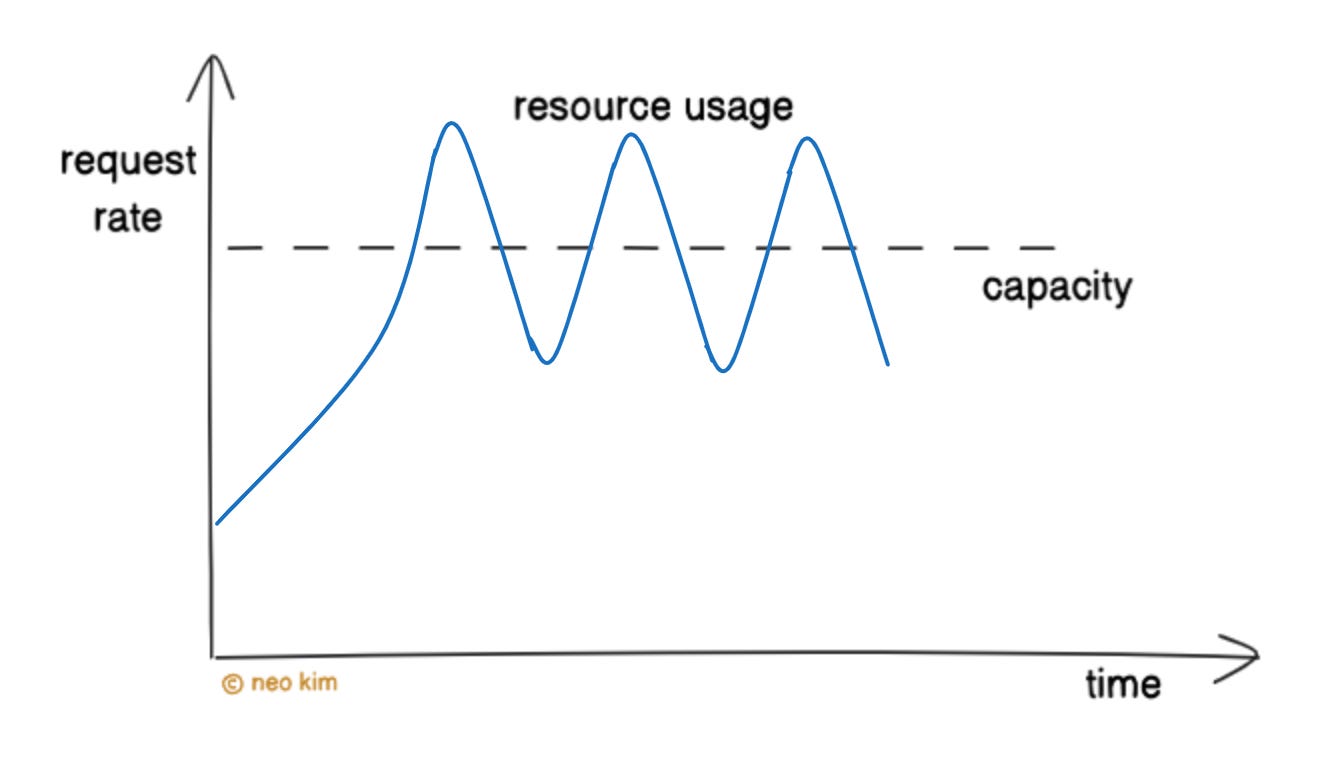
Here’s how it works:
They use a technique similar to TCP congestion control for throttling.
Rate limiter throttles requests upon a backpressure signal from the backend service. For example, they track error, latency, and capacity.
And then slowly increases the requests to those backend services.
On congestion detection, it throttles requests again.
Yet it throttles only the functions that call backend services for performance.
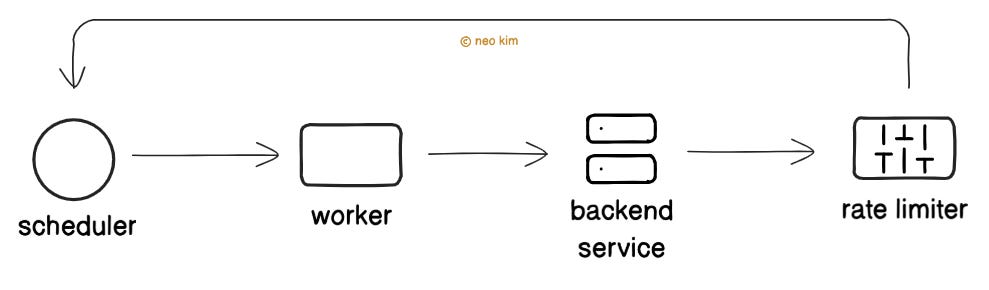
Besides it’s necessary to control the number of concurrent functions calling a backend service to prevent overload.
So they start with fewer concurrent function requests. This gives backend services enough time to warm up their cache and handle the load.
3. Peak Traffic
It’s necessary to prevent a function from using up the resources during peak traffic.
So they assign a limit to how many times a function can run or how many resources it can use. After a function reaches that limit, it’s throttled.
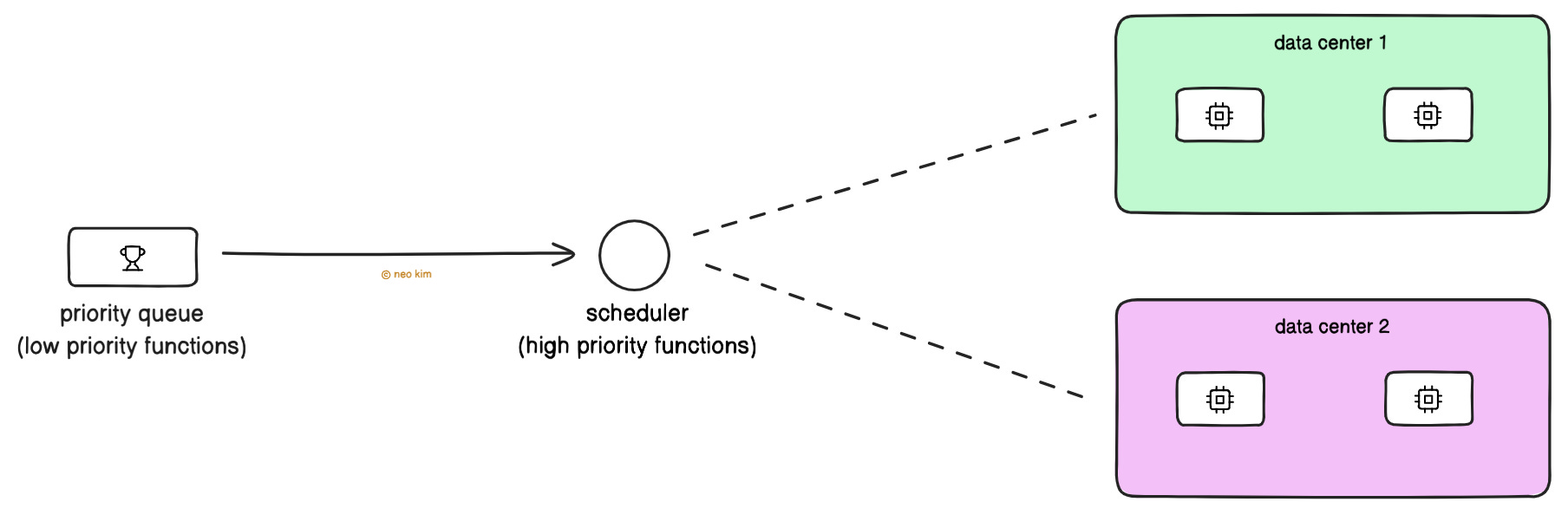
Also they distribute function execution across data centers to distribute the load evenly. And delay the low-priority functions until low-traffic hours16. Put simply, they run specific functions only when there’s enough free server capacity.
Besides most services are stateless and replicated for scalability and fault tolerance. While stateful services are partitioned and replicated.
Ready for the best part?
Keep reading with a 7-day free trial
Subscribe to The System Design Newsletter to keep reading this post and get 7 days of free access to the full post archives.