
How Stock Exchange Processes 6 Million Events per Second with Microsecond Latency
#104: Stock Exchange System Design - Part 2


Share this post & I’ll send you some rewards for the referrals.
I created block diagrams for this newsletter using Eraser.
This month, I launched Design, Build, Scale… the newsletter series that will elevate your software engineering career.
This is Part 2 of how a stock exchange works.
Let’s start with a TL;DR of Part 1!
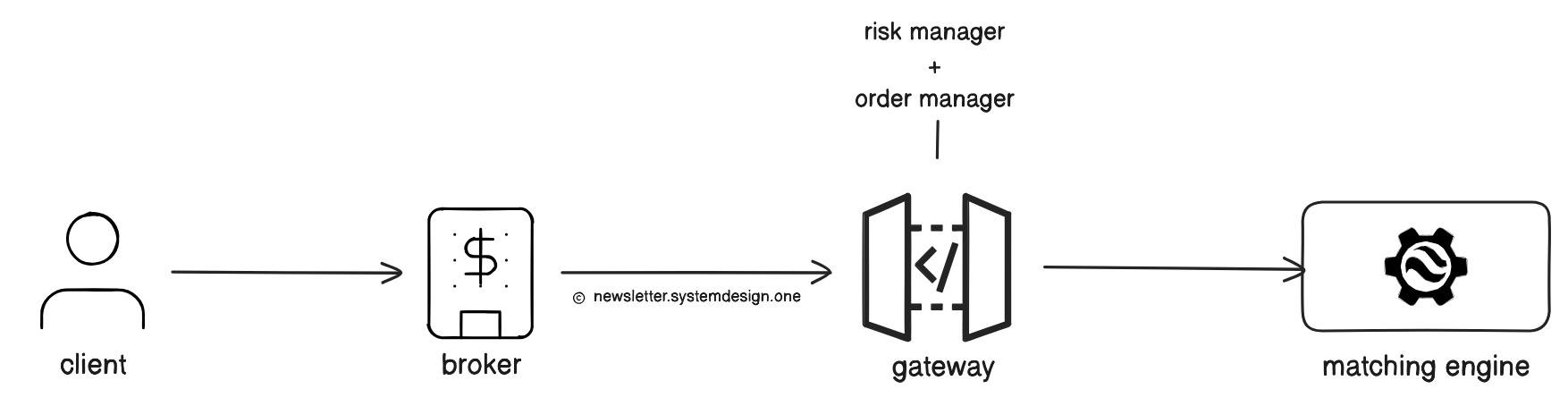
Three key components of an exchange are:
Broker - allows people to buy and sell stocks on the exchange.
Gateway - entry point for brokers to send BUY or SELL orders to the exchange.
Matching Engine - a component that matches BUY and SELL orders to create trades.
A stock market reduces latency by avoiding unnecessary services in the critical path.
BUT… threads have to pass events efficiently to achieve “ultra-low” latency at scale.
Examples:
New order event,
Risk check event,
Cancel order event,
Trade execution event,
Market data update event,
Replication or Journal event.
So the concurrency model matters!
Onward.
EverMemOS—The Next-Generation AI Memory System (Sponsor)

Most AI agents forget everything after a session—making them inconsistent, hard to debug, and impossible to scale.
Inspired by human brain memory mechanisms, EverMemOS provides an open-source memory OS that supports 1-on-1 conversation scenarios and complex multi-agent workflows. As reported, EverMemOS achieved 92.4% on LoCoMo and 82% on LongMemEval-S, both SOTA results of the two benchmarks.
Later this year, EverMind will launch the cloud service version, offering enterprise users advanced technical support, persistent storage, and scalable infrastructure.
If you’re building agentic apps, EverMemOS gives you the memory layer you’ve been missing.
Most system design goo-roos think using locks, or queues, or message brokers is enough.
They’re WRONG…
Here’s why:
1 Locking
There are two key locking models:
Pessimistic,
Optimistic.
Pessimistic locking
A thread acquires a lock before touching shared data. So other threads must wait until the lock gets released. This means only one thread can update the shared data at a time.
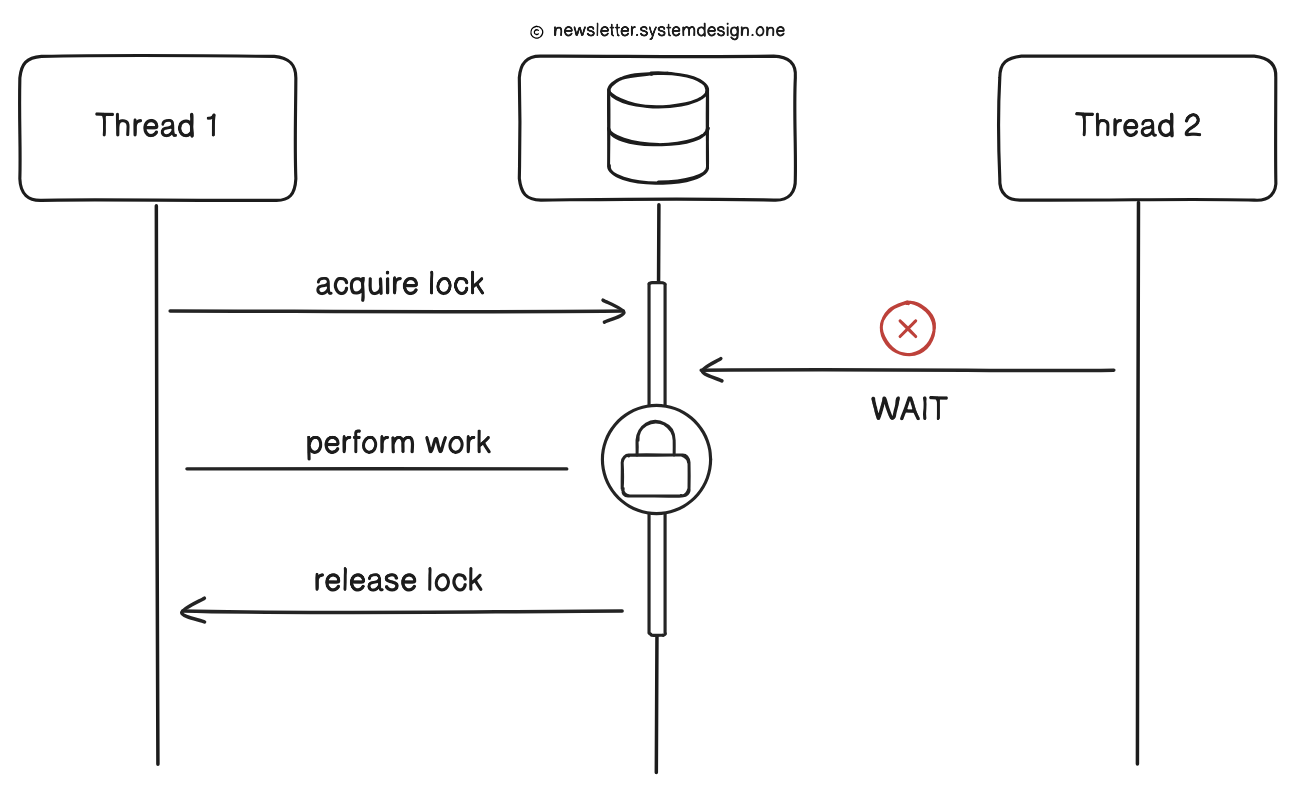
But on a stock exchange:
Many threads try to read or update the same data at scale.
And locks force them to wait in line, which causes latency spikes.
More threads → more blocking → much SLOWER.
Even a single lock can slow down a thread by 10x, and with many threads, performance could drop 100x.
Besides, there’s also a risk of deadlock1 if two threads wait on each other.
So this approach wouldn’t work for a stock exchange.
Optimistic locking
It doesn’t use traditional locks; instead, it uses compare-and-swap (CAS) to detect conflicts.
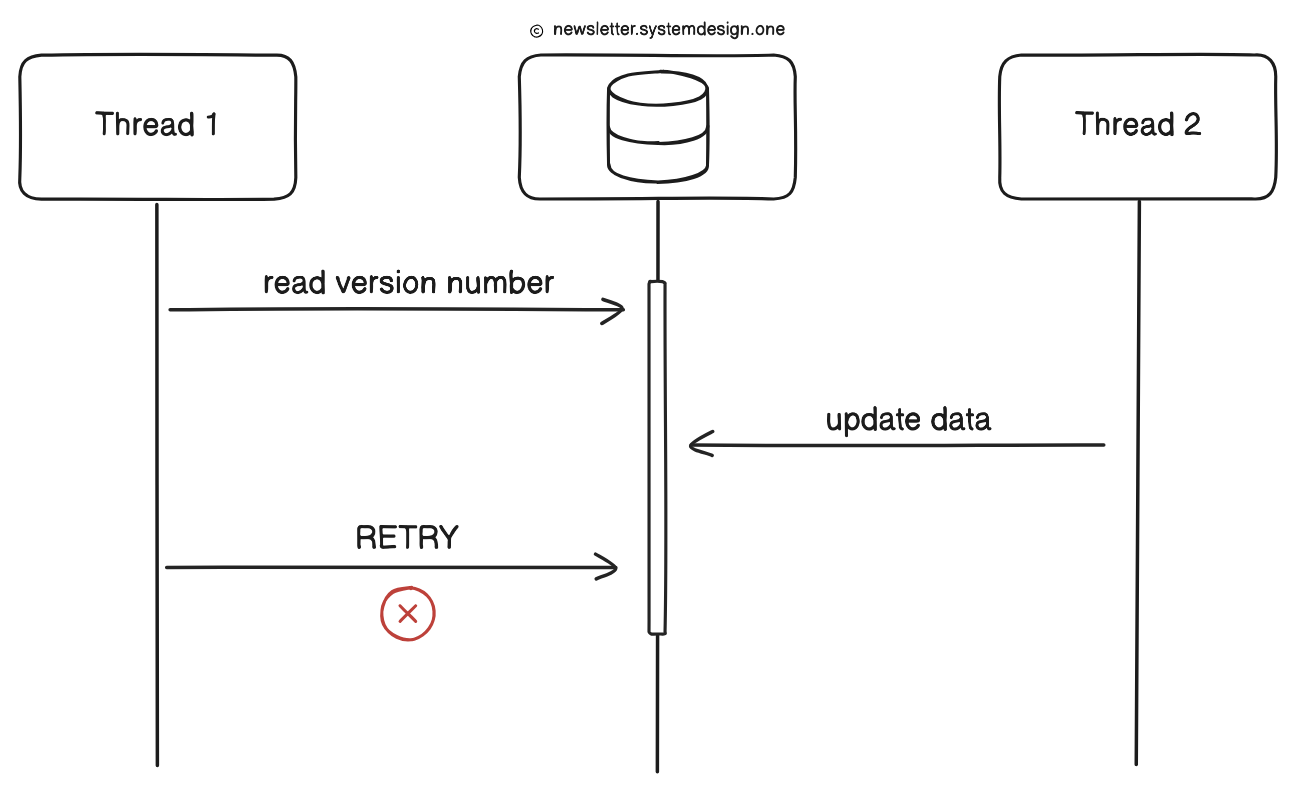
Here’s how:
A thread reads shared data + its version.
Then it writes new data only if the original version hasn’t changed in the meantime.
If another thread updates it first, the write fails, and the thread has to RETRY.
This technique works well when conflicts are rare,,, but on a stock exchange:
Many threads try to change hot data (sequence counters, and so on).
Thus CAS failures become more frequent, and spin + retry loops waste CPU.
So performance weakens at scale.
2 Traditional Queues (ArrayBlockingQueue)
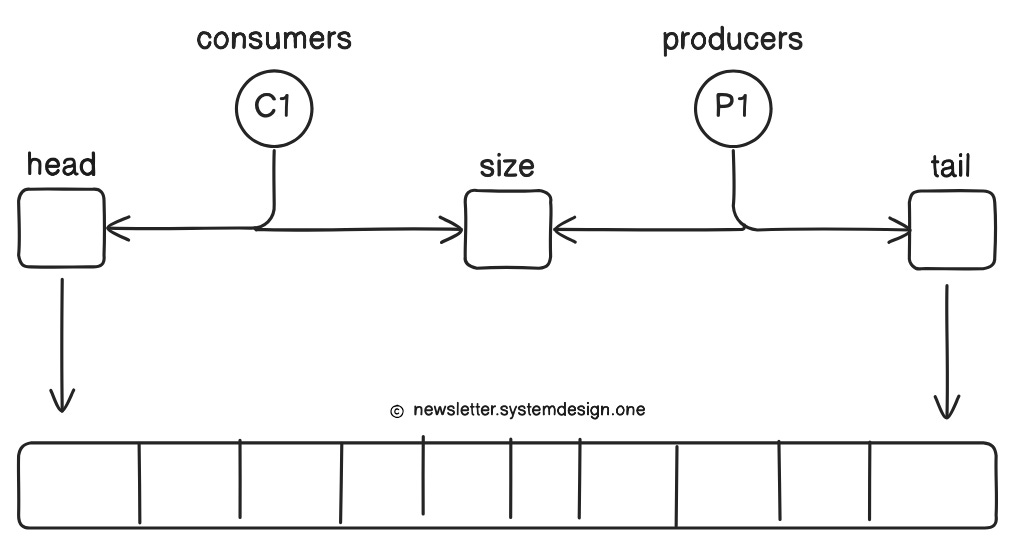
A Queue has:
Head (where consumers read from)
Tail (where producers write to)
Yet when there are many threads at once:
Consumers compete to update the head,
Producers compete to update the tail.
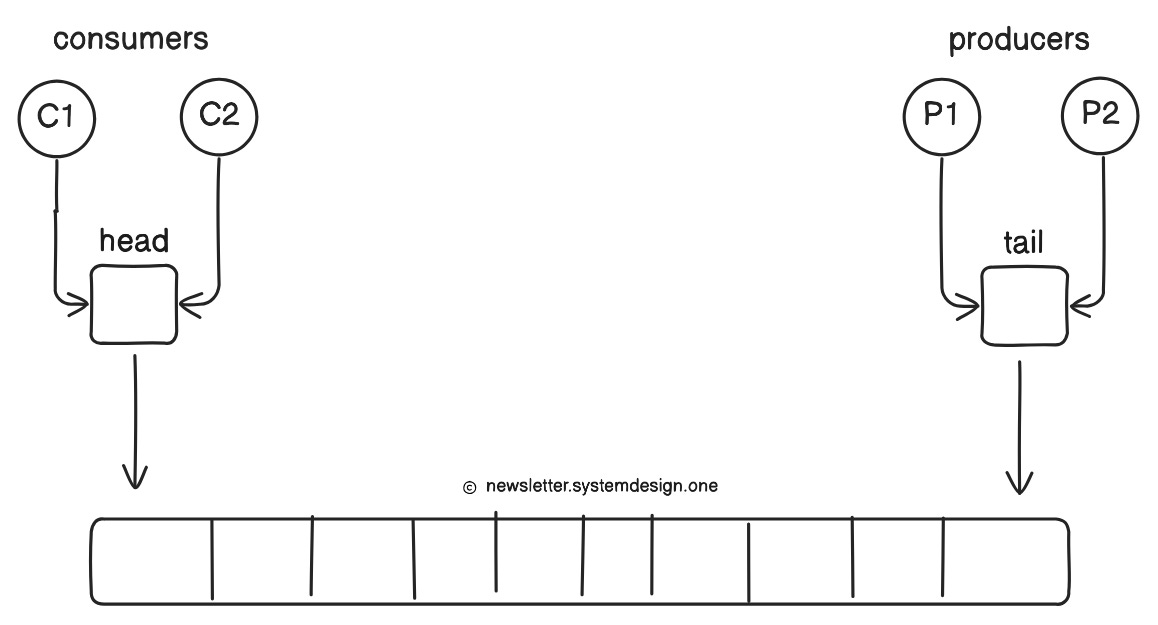
This creates contention and forces locking or other synchronization techniques… which slows everything down.
Plus, head, tail, and size variables are often on the same CPU cache line2.
NOTE: A CPU reads and writes memory in chunks (usually 64 bytes) called cache lines, not single variables.
So there’s a risk of false sharing3 when:
Two threads update different variables
And those variables live on the same cache line
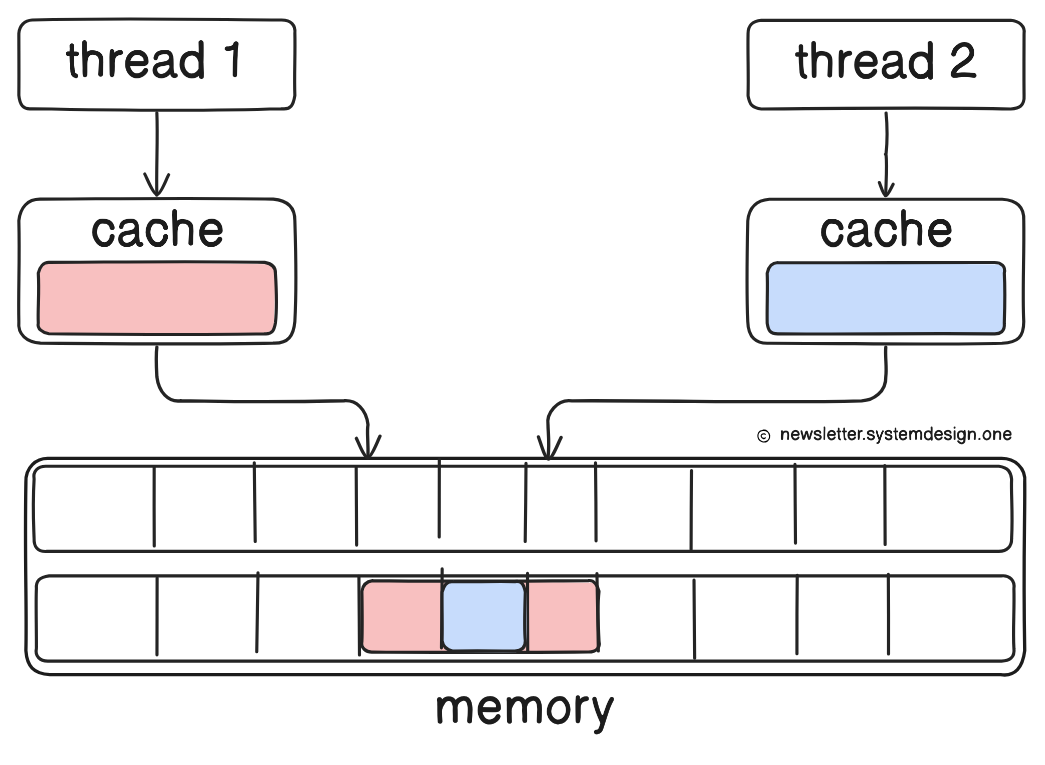
Even though the threads aren’t sharing data (i.e., no locks), the hardware thinks they’re, causing:
massive slowdowns
constant cache invalidations
This is a performance problem for traditional queues under high concurrency.
Also, a queue is often:
Full (because producers are fast)
Or empty (because consumers are fast)
So producers/consumers constantly fight over the same memory region. And this causes contention.
Besides, in some implementations, reads may require writes when consumed. This also causes contention.
3 Message Brokers
Message brokers like Kafka and RabbitMQ are built for general messaging... NOT for microsecond latency.
They introduce extra overhead because of:
serialization,
buffering,
network hops.
Plus, their queues use locks and background threads, which add jitter.
So they’re too slow for a stock exchange!
Then how do you achieve “ultra-low” latency at SCALE?
Reminder: this is a teaser of the subscriber-only newsletter series, exclusive to my golden members.

When you upgrade, you’ll get:
High-level architecture of real-world systems.
Deep dive into how popular real-world systems actually work.
How real-world systems handle scale, reliability, and performance.
Keep reading with a 7-day free trial
Subscribe to The System Design Newsletter to keep reading this post and get 7 days of free access to the full post archives.